森田です。
前回の記事で blocknote と yjs と liveblocks を用いた共同編集の実装を紹介しました。
とても簡単に実装できるというは大きな利点なのですが、これは Nextjs ありきの実装となっており、react ではどう実装するのという話になってしまいます。
なので今回は React + Rails の構成で yjs と ActionCable を用いたコンフリクトフリーな共同編集を実装してみましょう!
Rails は開発環境構築が完了しており、5000 ポートで立ち上がる前提で進めます。 フロントは Vite + React で開発します。
実装
Rails
まずActionCableを使うにあたって必要なgemをインポートしておきます。
require "action_cable/engine"
続いて開発環境のみでどのオリジンからもActionCableに接続できるようにしておきます。 該当する行のコメントアウトを外すだけです。
config.action_cable.disable_request_forgery_protection = true
では実際にActionCableを作成してみましょう。
ストリーム先を自由に選択できるようにしたいので、idによって変化するようにします。
class SyncChannel < ApplicationCable::Channel
def subscribed
document_id = params[:id]
stream_from("document-#{document_id}")
end
def receive(message)
document_id = params[:id]
ActionCable.server.broadcast("document-#{document_id}", message)
end
end
React
続いてフロント側の実装をしていきます。
まず必要なライブラリをインポートしていきます。
npm i @rails/actioncable @types/rails_actioncable @y-rb/actioncable
おやおや?
何やら怪しいライブラリが含まれていますね...
y-rb/actioncableとはなんぞや?と思われたそこのあなた。鋭いですねぇ
今回も前回と同様にyjsというフレームワークを用いてコンフリクトフリーな共同編集を実装します。 ところがyjsはjsと付いているようにjavascriptを前提に作られているフレームワークです。 なのでrailsで扱うには少し不都合なのです。
そこで登場するのがこのy-rb/actioncableです。 公式の説明を簡単に翻訳すると、「yjsクライアントとRailsのActionCableチャネルを使用してWebSocket接続を設定するために必要なJavaScriptとRubyの依存関係を提供してくれる」とのことです。
詳しくはこちら↓
https://github.com/y-crdt/yrb-actioncable
こんな便利なものがあるなら使わない手はないということでしっかり組み込んでフロントを実装していきましょう。
BlockNote関連の部分は前回の記事を参照ください。
import { WebsocketProvider } from "@y-rb/actioncable";
import { createConsumer } from "@rails/actioncable";
import * as Y from "yjs";
import { useEffect, useState } from "react";
import { BlockNoteEditor } from "@blocknote/core";
import { useCreateBlockNote } from "@blocknote/react";
import { BlockNoteView } from "@blocknote/mantine";
import "@blocknote/core/fonts/inter.css";
import "@blocknote/mantine/style.css";
export const App = () => {
const [doc, setDoc] = useState<Y.Doc>();
const [provider, setProvider] = useState<any>();
useEffect(() => {
const consumer = createConsumer("ws://localhost:5000/cable");
const yDoc = new Y.Doc();
const yProvider = new WebsocketProvider(yDoc, consumer, "SyncChannel", { id: "1" });
setDoc(yDoc);
setProvider(yProvider);
return () => {
yDoc?.destroy();
yProvider?.destroy();
};
}, []);
if (!doc || !provider) {
return null;
}
return <BlockNote doc={doc} provider={provider} />;
};
type EditorProps = {
doc: Y.Doc;
provider: any;
};
function BlockNote({ doc, provider }: EditorProps) {
const editor: BlockNoteEditor = useCreateBlockNote({
collaboration: {
provider,
fragment: doc.getXmlFragment("document-store"),
user: {
name: "User",
color: "#ff0000",
},
},
});
return <BlockNoteView editor={editor} />;
}
実装はほとんど前回と一緒ですね。
const consumer = createConsumer("ws://localhost:5000/cable");
@rails/actioncable"を用いてcosumerを設定しています。今回Railsを5000ポートで立ち上げているのため上記のようになっているので、ここはそれぞれの環境に合わせて書き換えてください。
const yProvider = new WebsocketProvider(yDoc, consumer, "SyncChannel", { id: "1" });
そして@y-rb/actioncableを用いてproviderを設定しているという感じですね。ここのidを変更することによってストリーム先を変更することができるので、必要に応じて変数にしたりしてみてください。
というわけで実装はここまで。
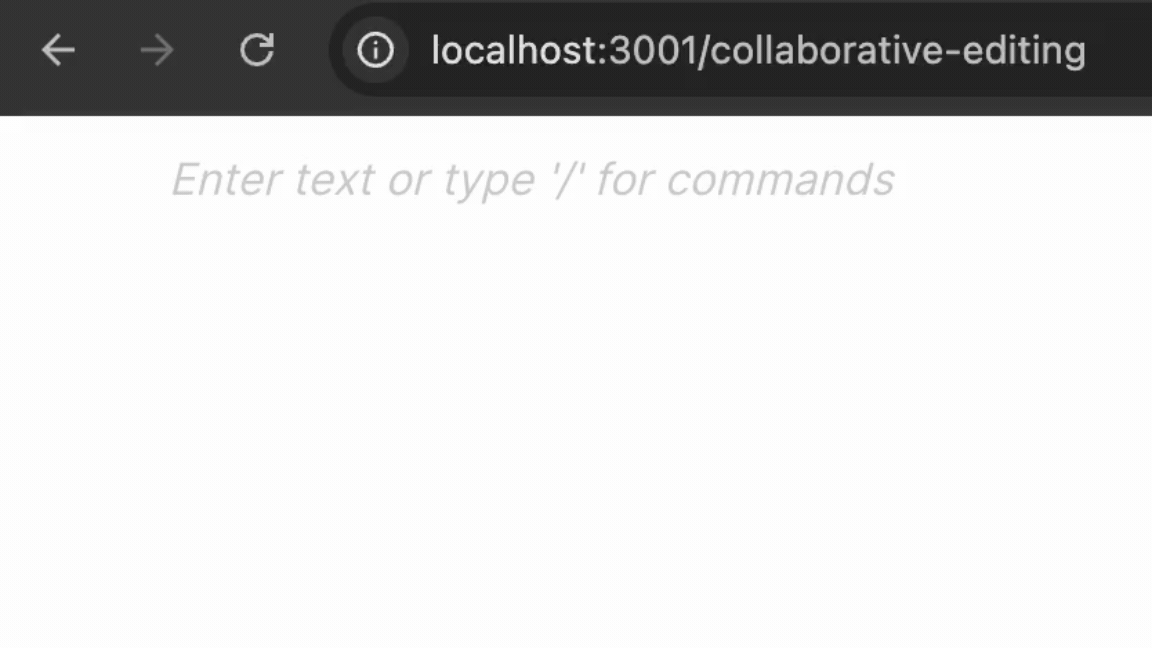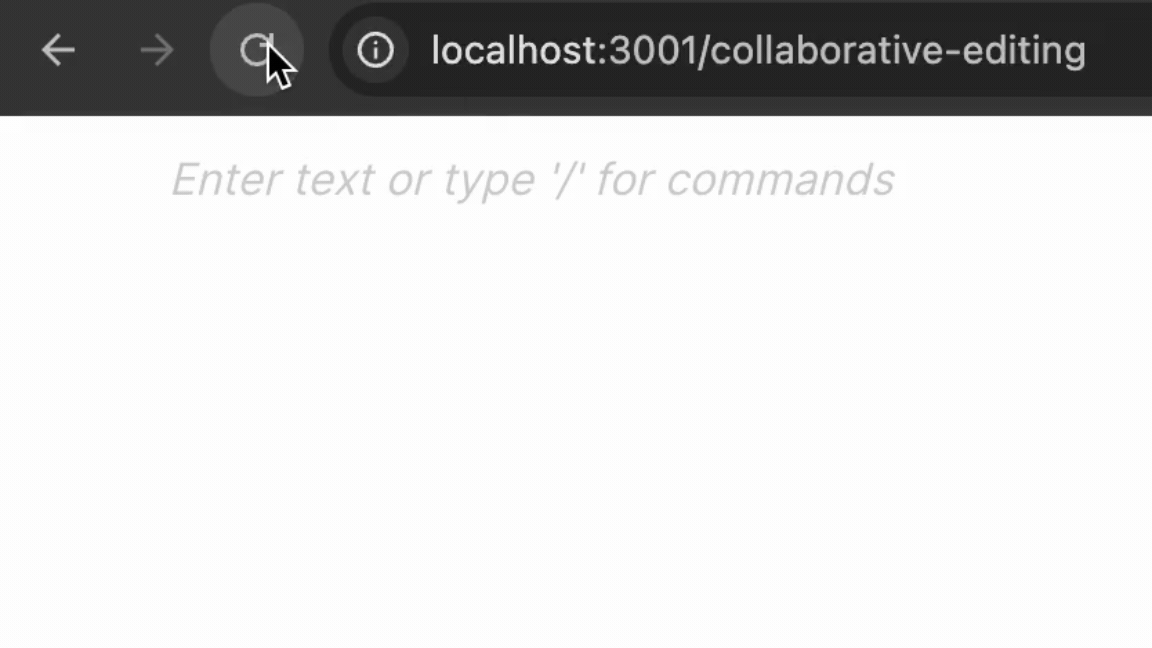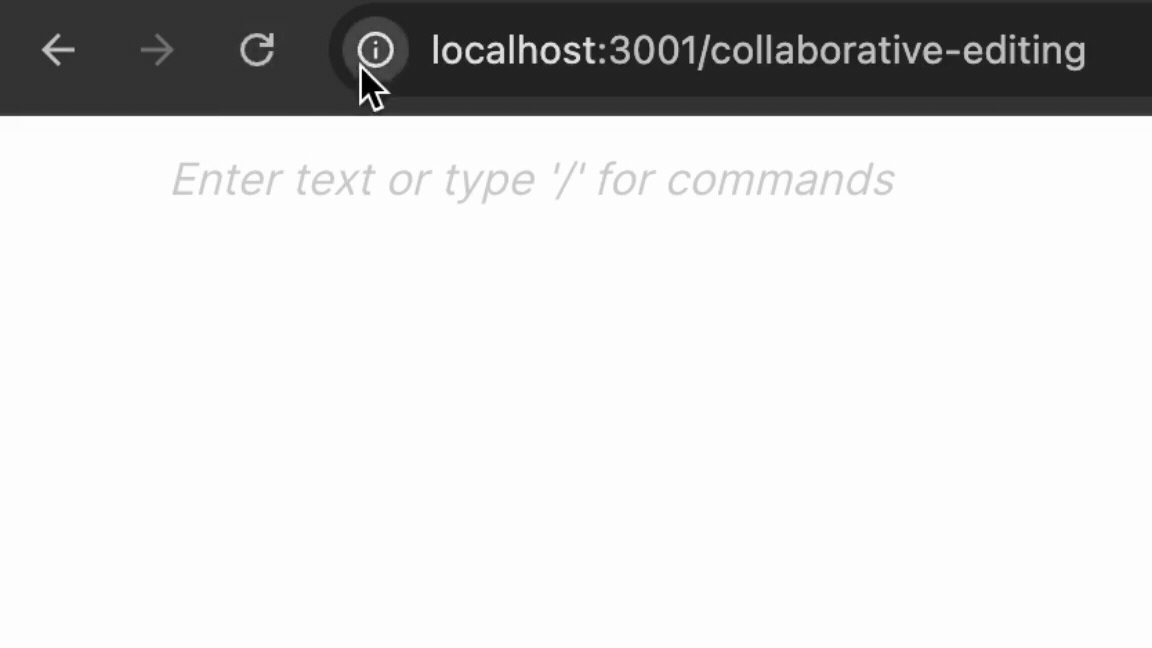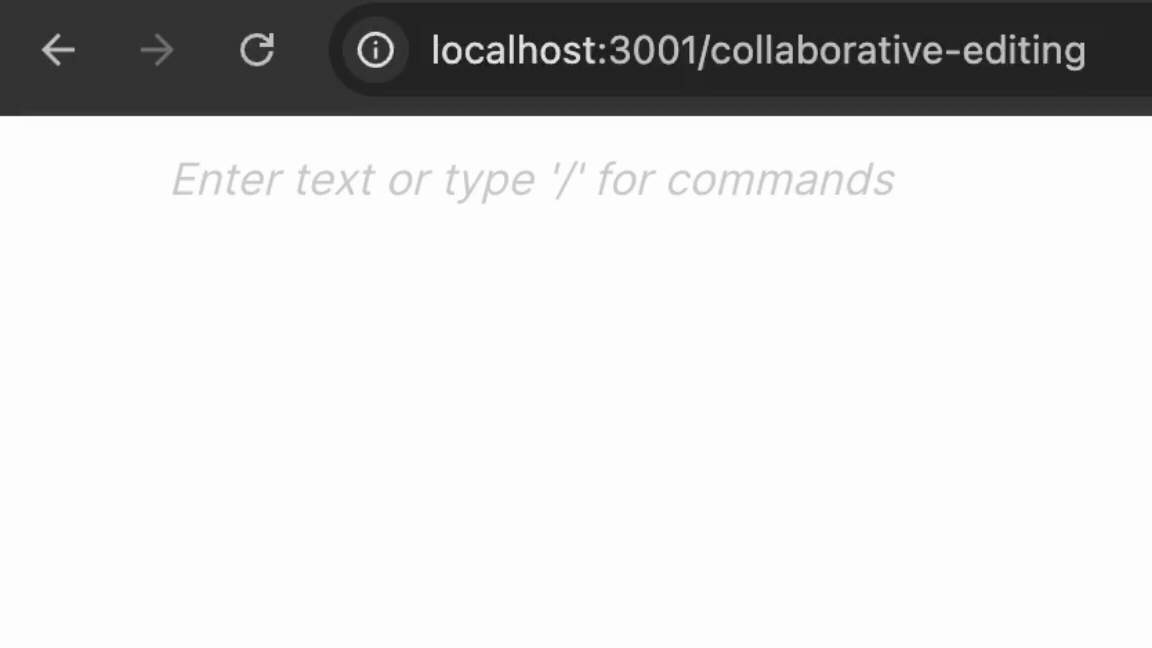
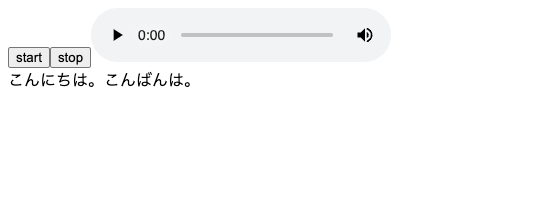
フロントとバックエンドそれぞれを立ち上げてみると...
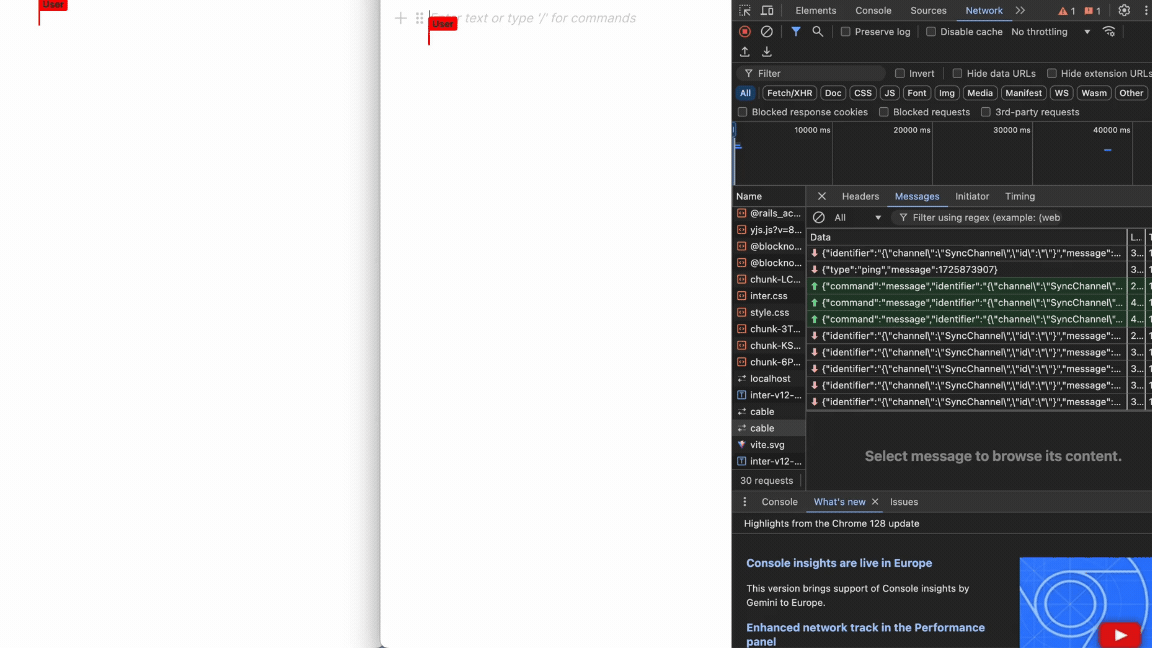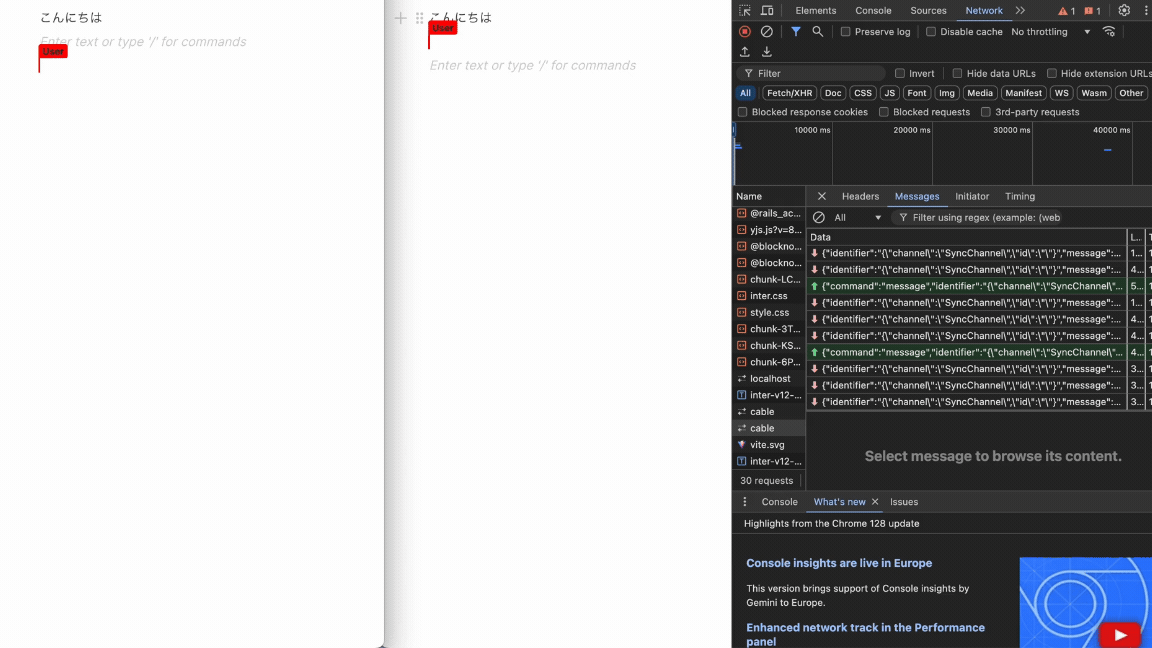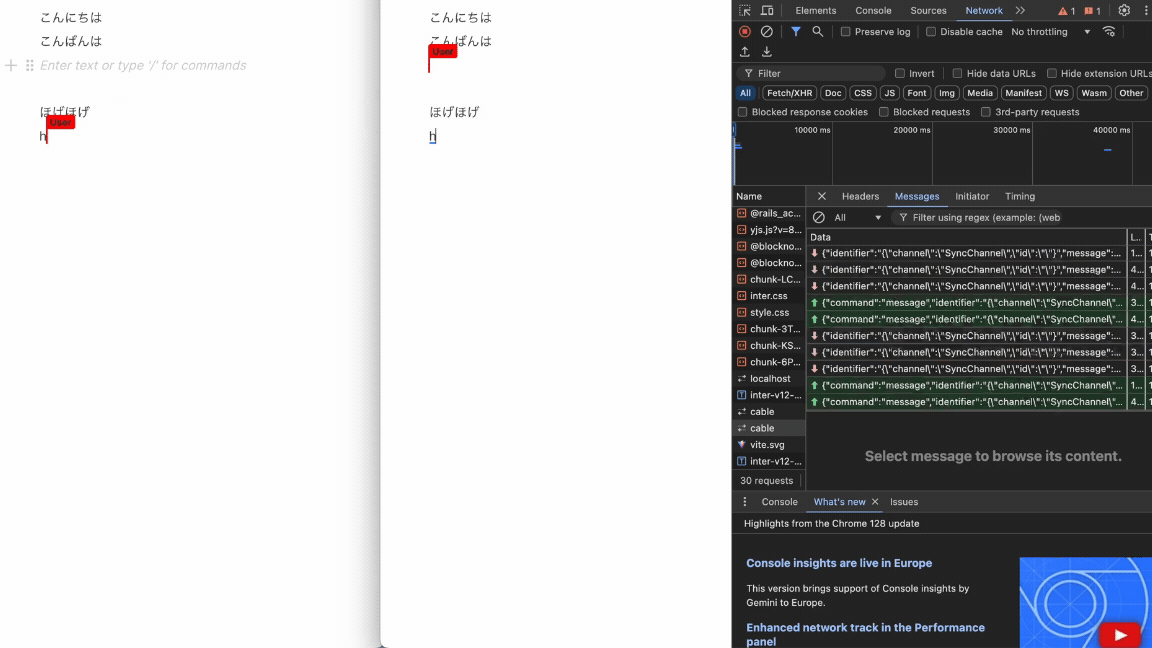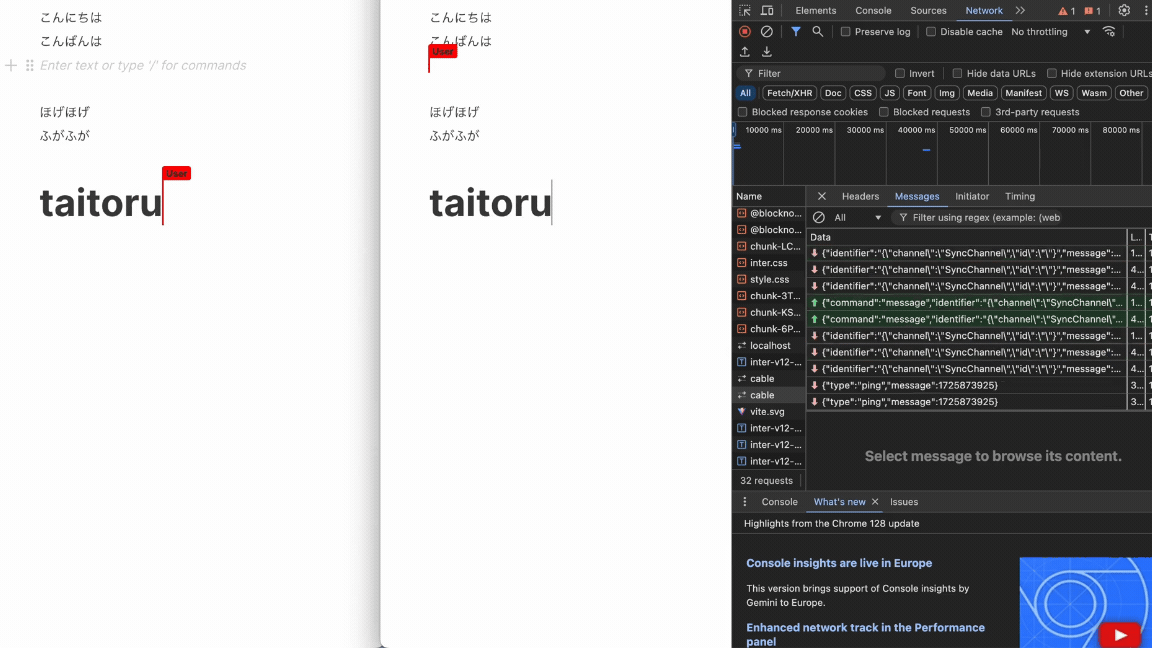
完成!🎉
課題
とりあえず共同編集はできるようにはなったのですが、この実装ではリロードすると記入内容が消えてしまいます。本来であれば、ActionCable側が接続されたことを感知してdbに保存されている内容を参照して送り返すという処理を挟むべきなのですが、yjsを使っているため従来のやり方ではできないのです。 今色々と試している段階なので、何か良い解決策が見つかったらまた記事にしてお届けしたいと思います。
終わり
というわけでyjsとActionCableを用いた共同編集の実装を紹介しました。ちゃんと動く状態になるまで試行錯誤してかなり時間がかかった記憶があるのですが、コードで見てみると結構簡単に実装できますね。 かなり拡張性のあるものだと思うので、ぜひ色々いじってみてください。何か面白いことができたりしたら逆に教えて欲しいです。
ではまた。
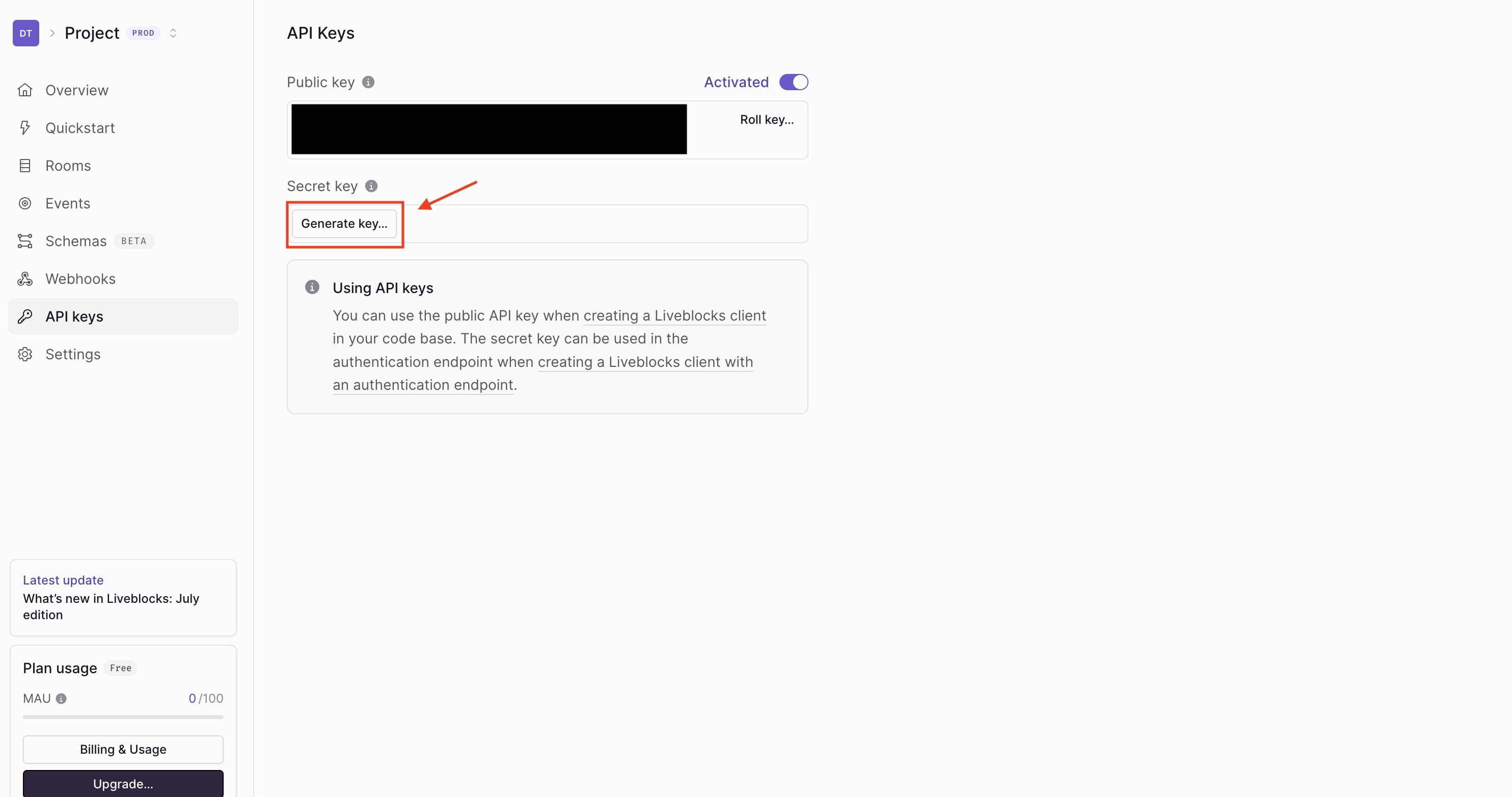
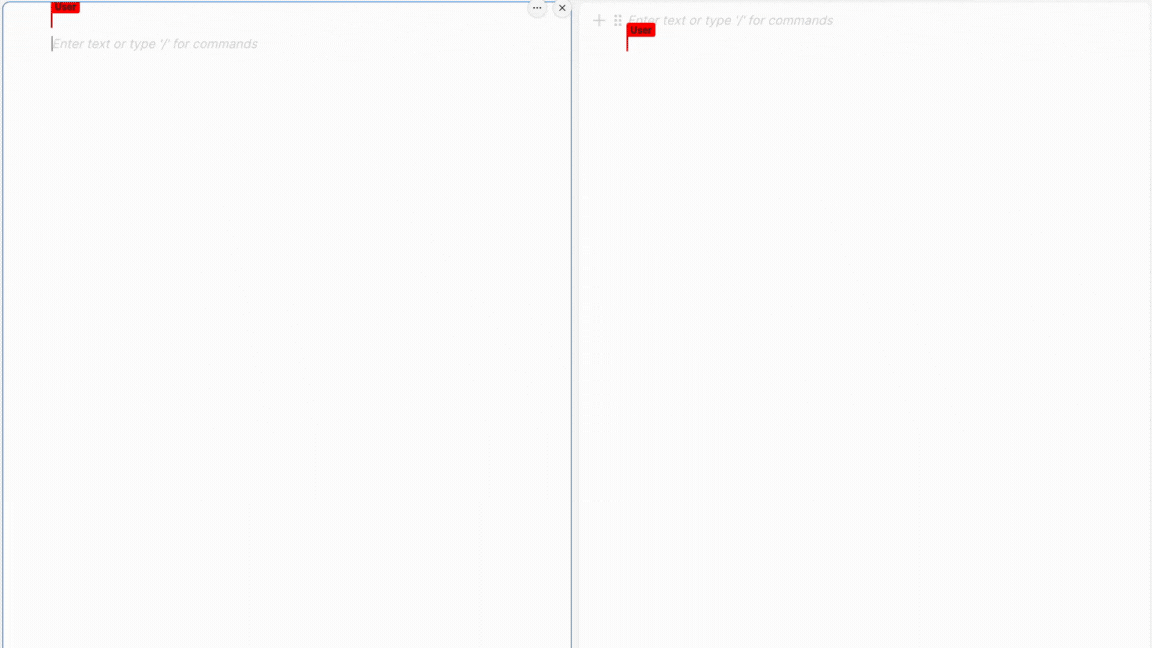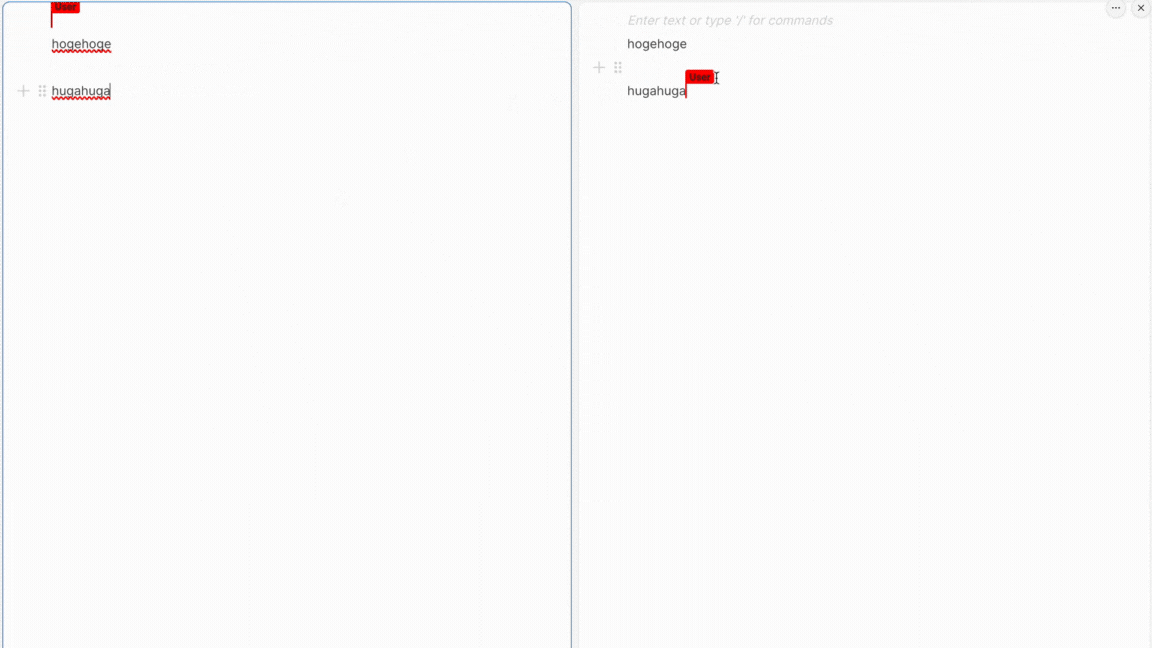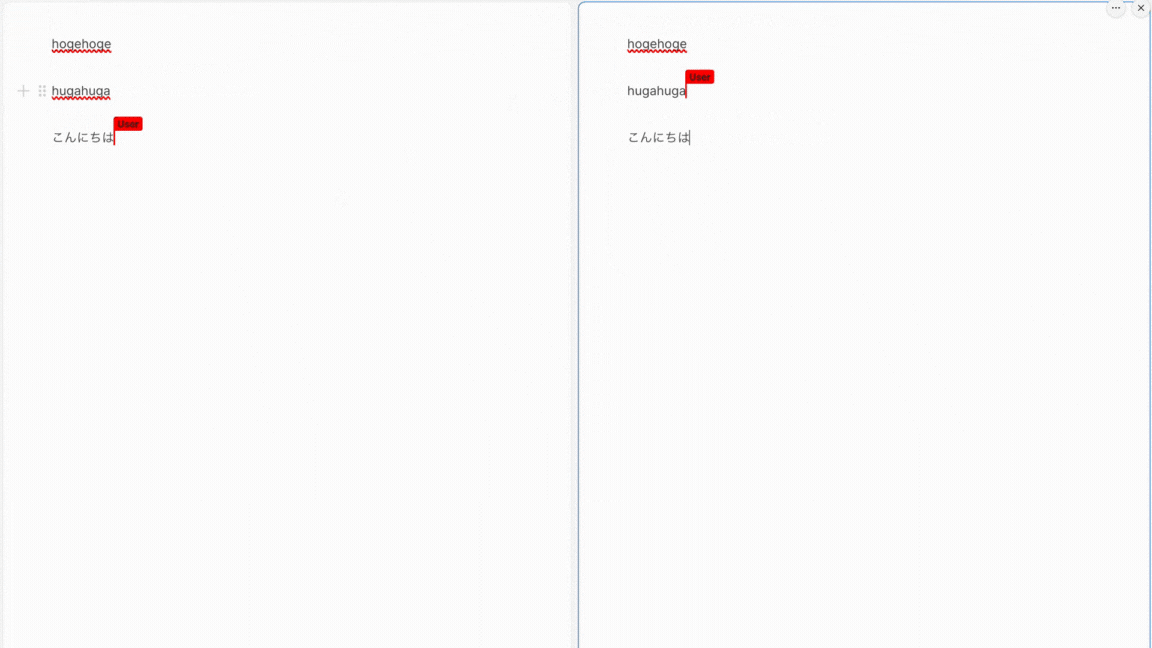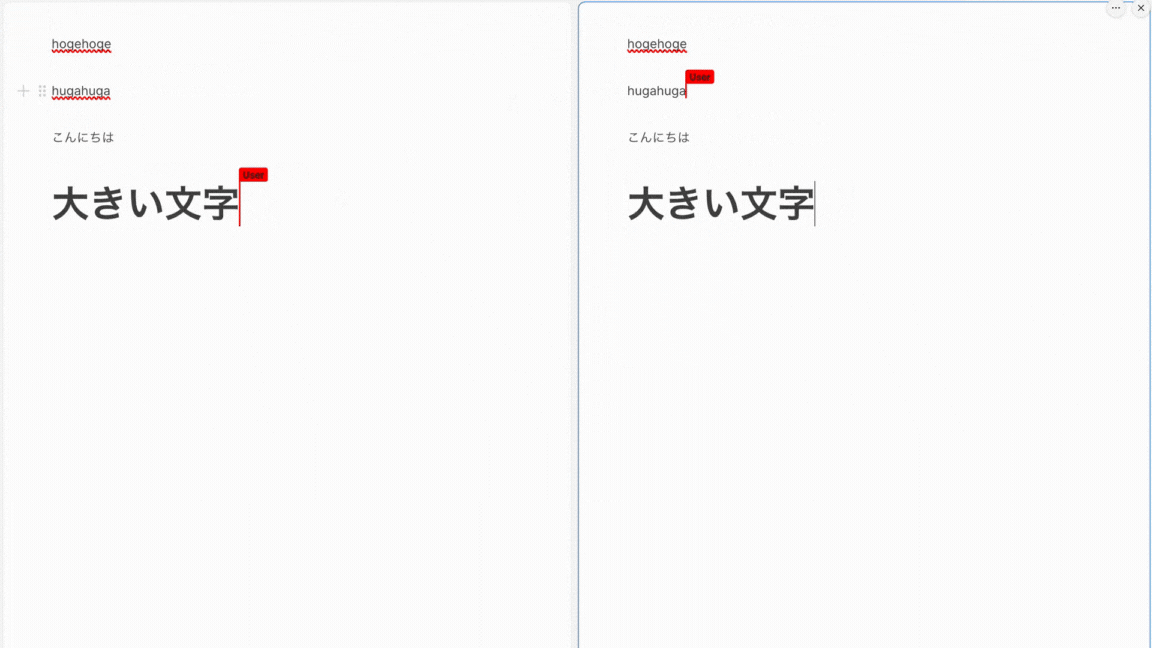






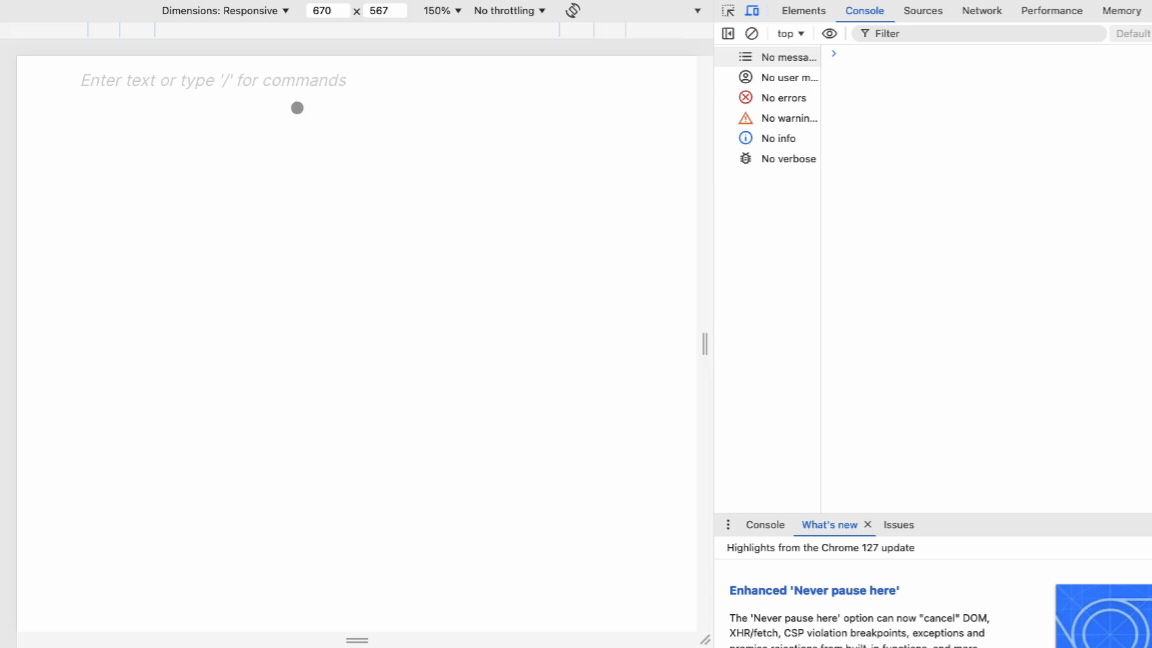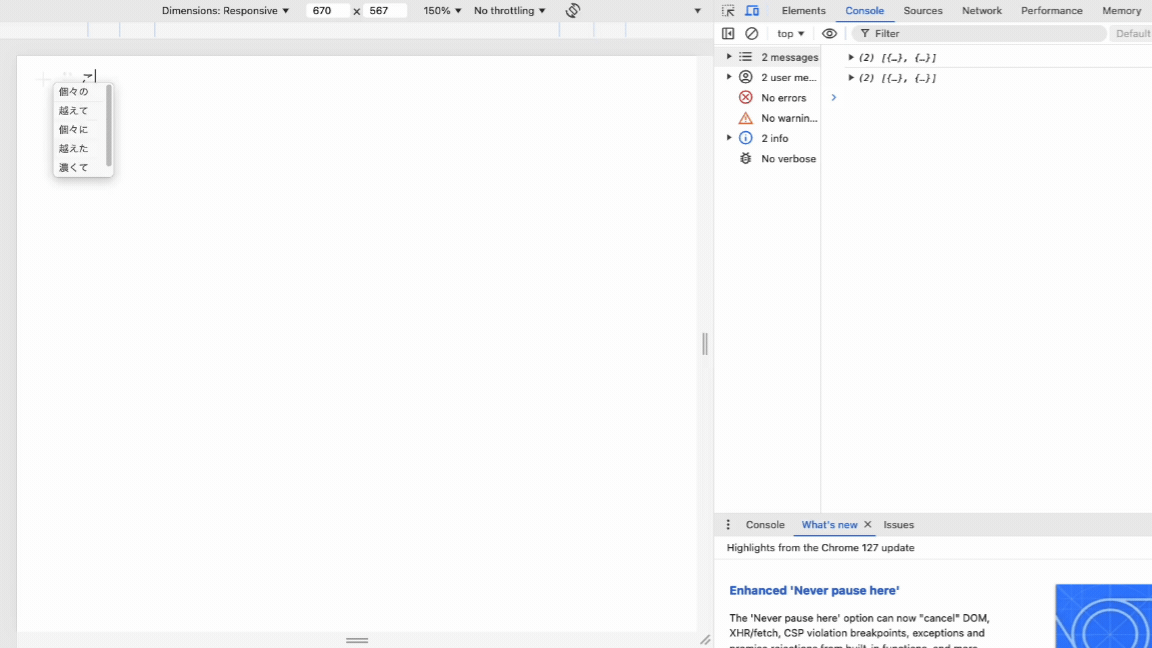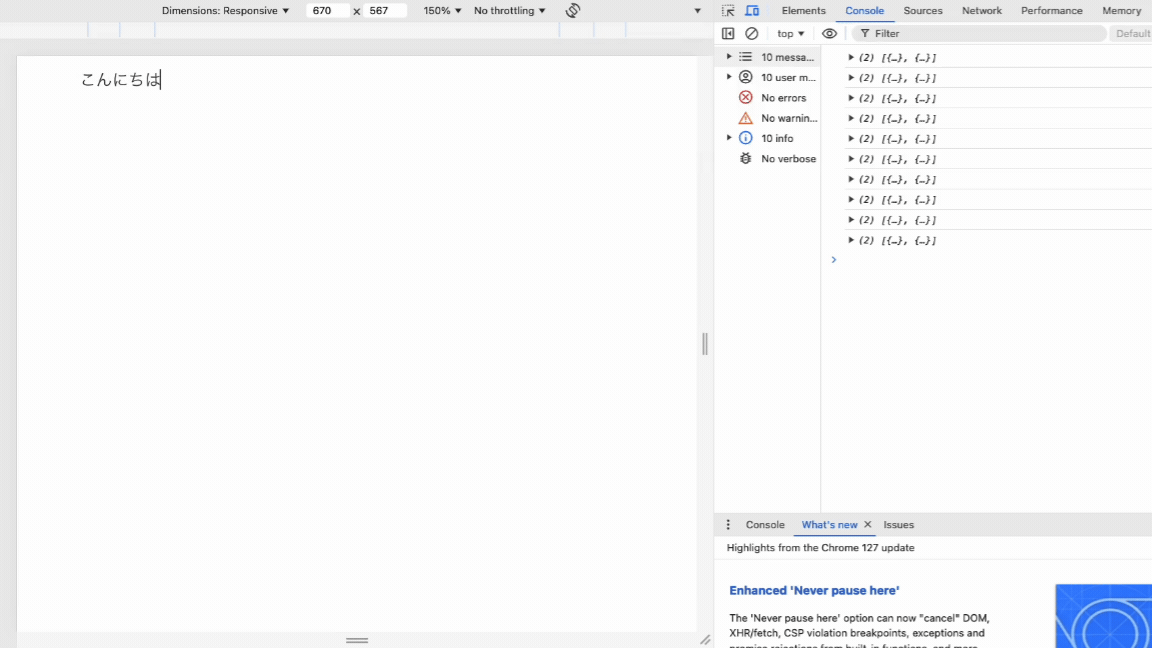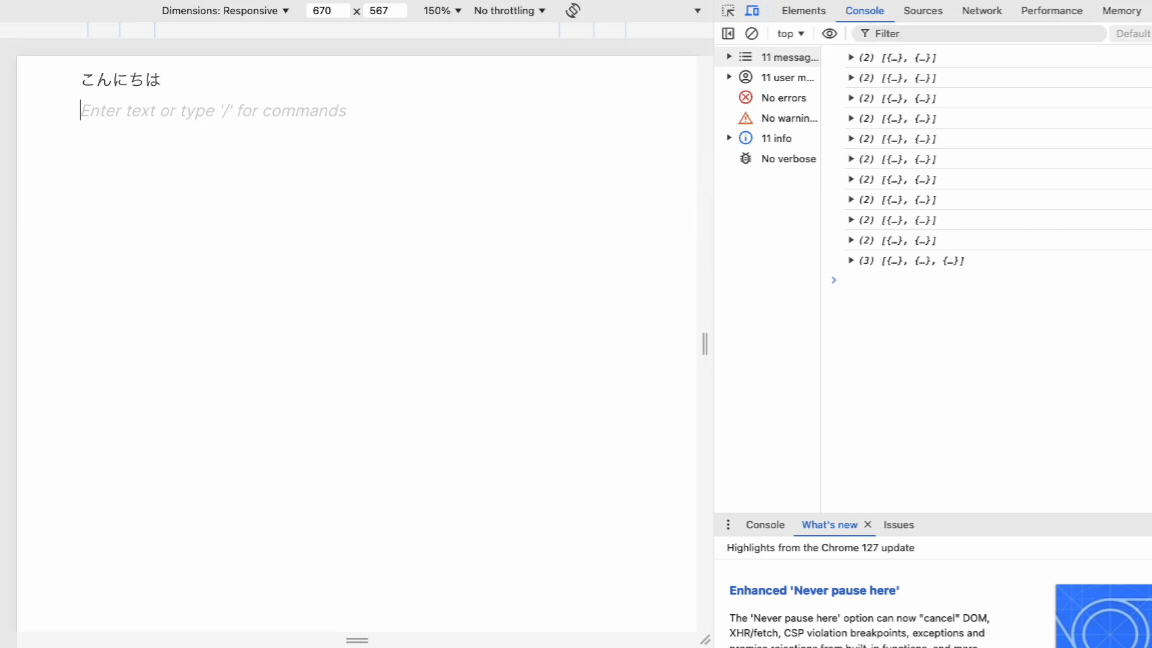
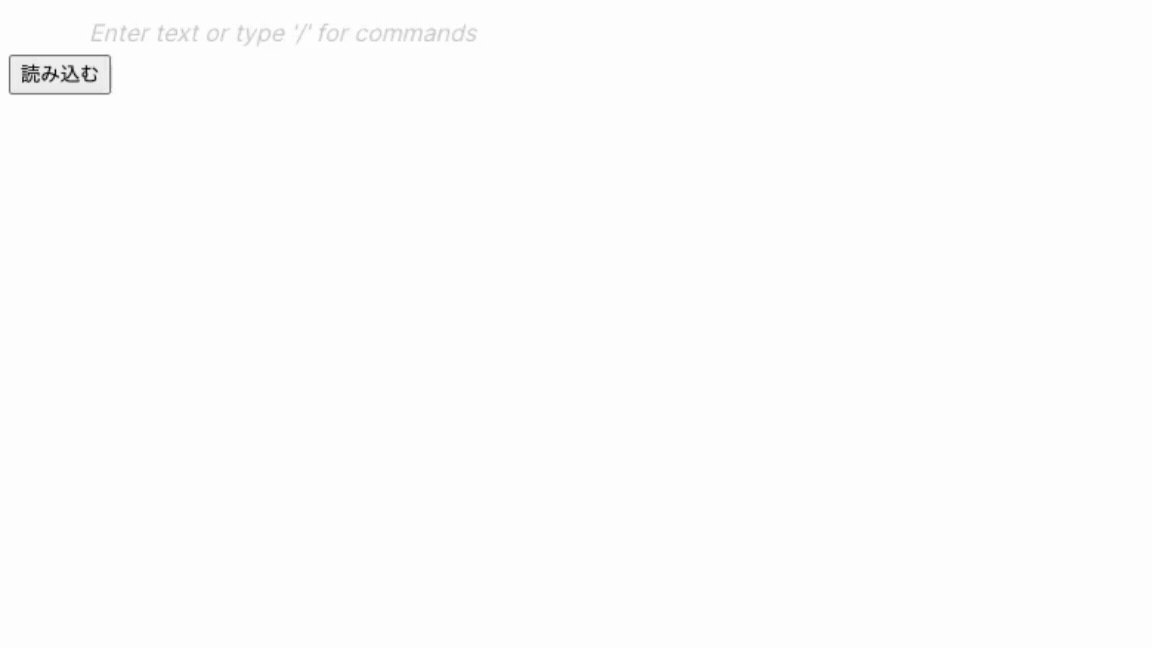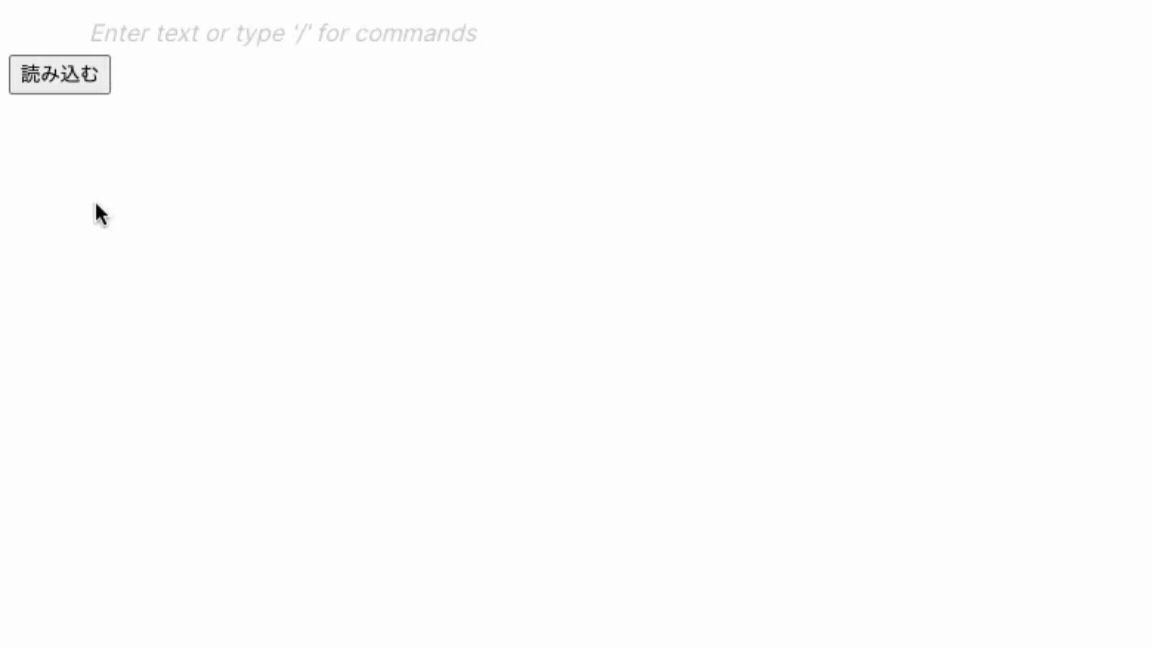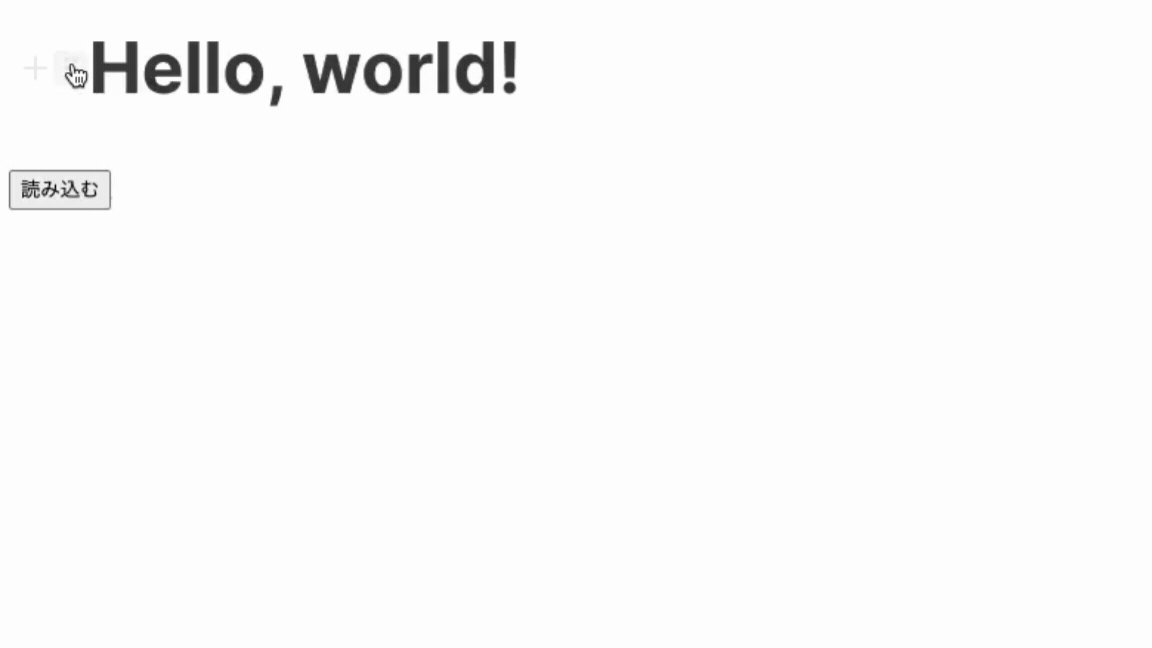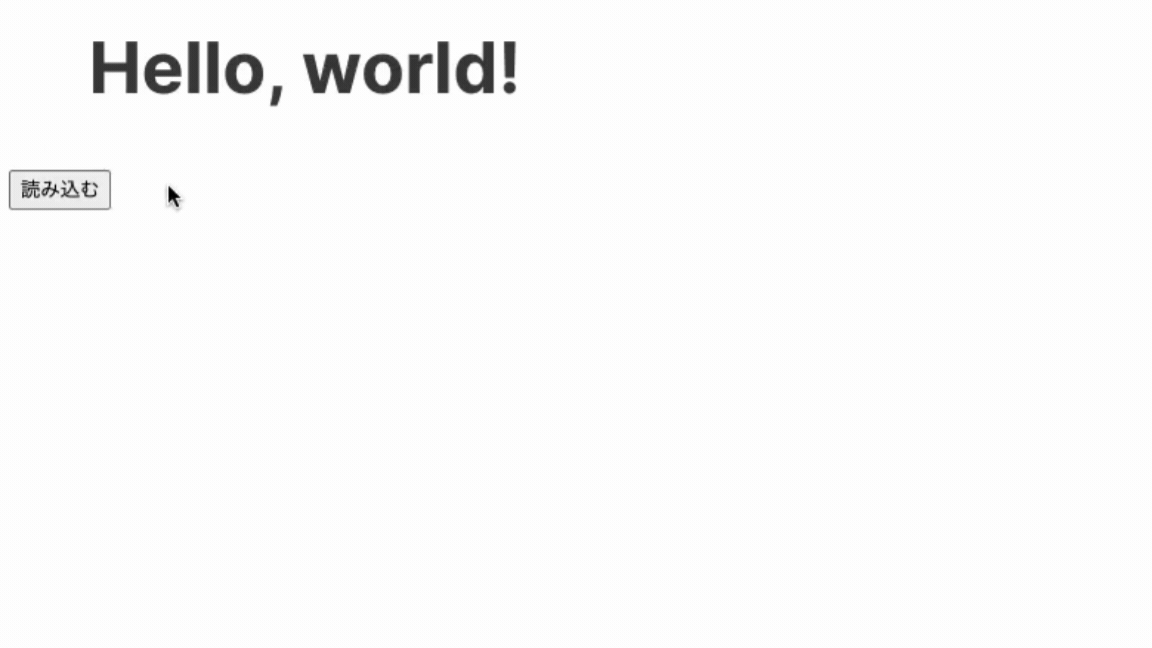






 これで取得完了です。
これで取得完了です。