
最近、業務でリアルタイム文字起こし実装する機会がありまして、Nextjs と Azure の Speech SDK で実装したのでその知見を書いていこうと思います。
https://learn.microsoft.com/ja-jp/azure/ai-services/speech-service/speech-sdk
Deepgram や Open AI の Whisper、文字おこしを実装するための API や SDK は様々あります。 今回 Azure Speech SDK を選んだ理由は大きく分けて2つあり、「精度の高さ」と「話者認識」です。
Azure Speech SDK はかなり感動するレベルで高精度かつ高感度な文字起こしをしてくれます。また、公式ドキュメントには話者分離の機能についても書いてあり、これも業務上使いたい機能でした。
ちなみにDeepgramや、Whisperなどの選択肢もあったのですが、精度や話者分離の機能などの観点から見送ることになりました。
実装
APIキーの準備
まず Azure の API キーを準備しましょう。
Azure のサービスページからリソースの作成
リソースの検索欄から Speech と入力
こちらを選択
プランを選択して作成
適当に入力して
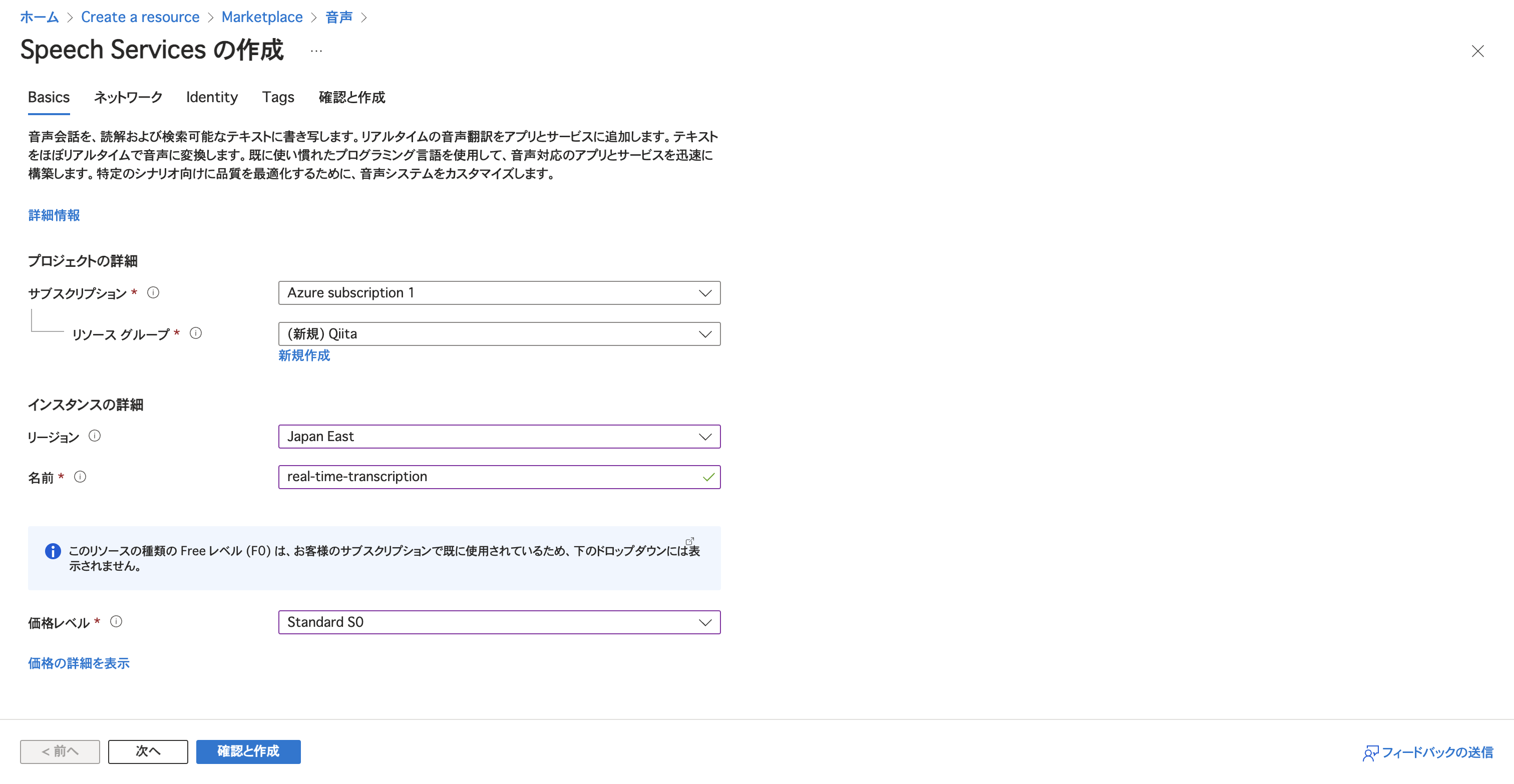
完了。リソースに移動して
キーの管理から
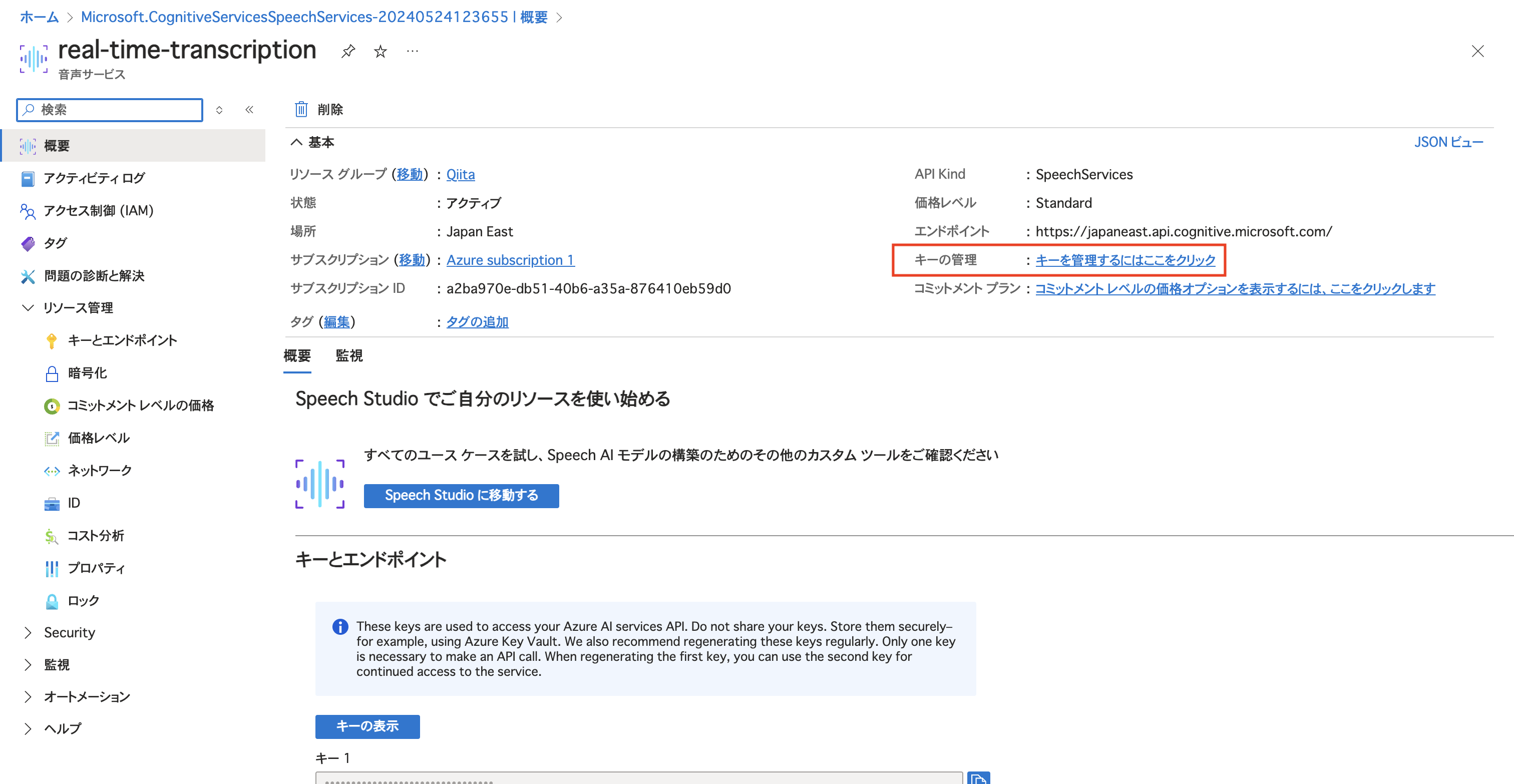
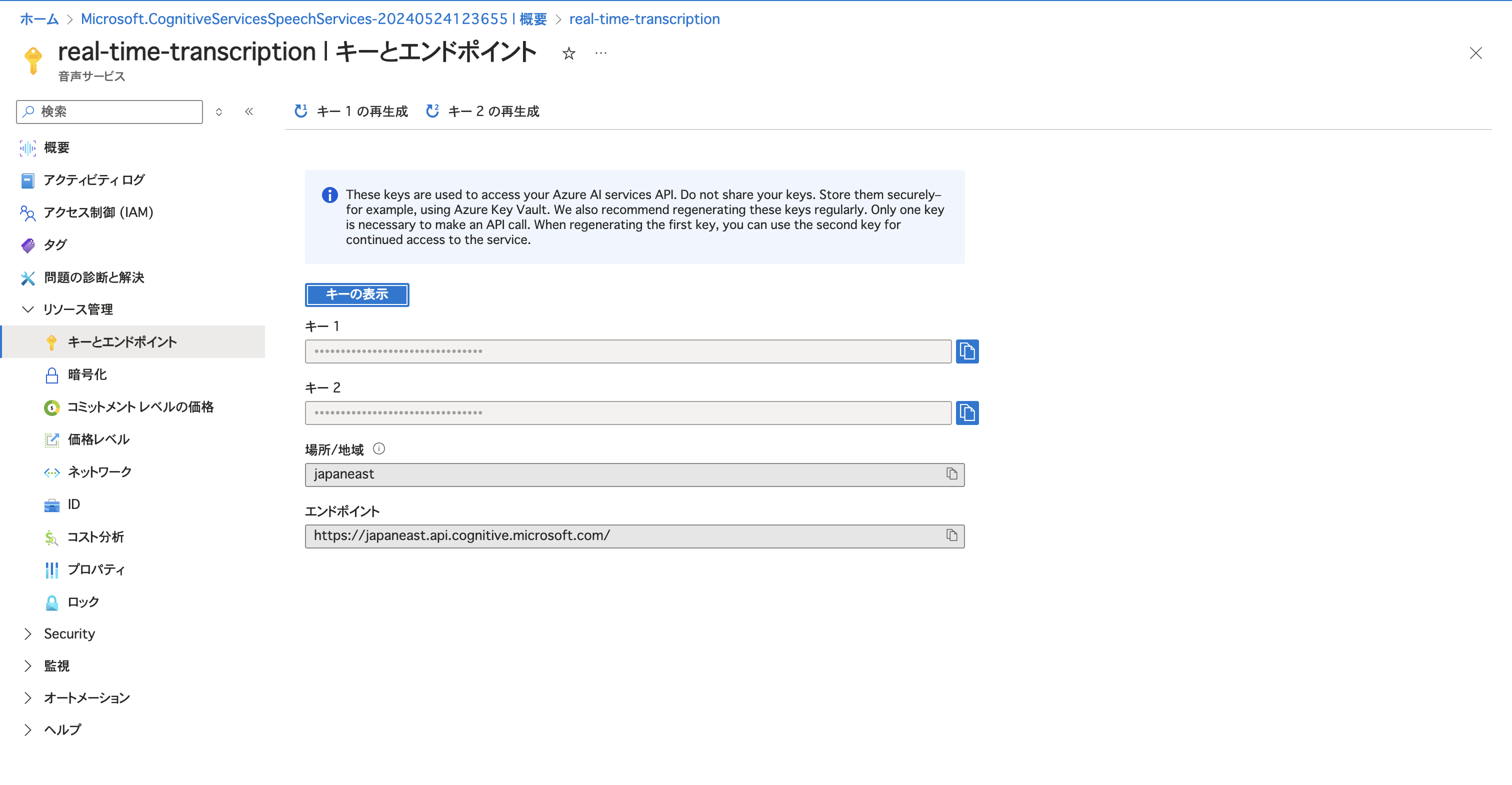
「キー1」と「場所/地域」を後で使うので保存しておきましょう。
Nextjs の実装
フロントを作っていきましょう。
新しい Nextjs プロジェクトの作成
$ npx create-next-app
✔ What is your project named? … real-time-transcription
✔ Would you like to use TypeScript? … Yes
✔ Would you like to use ESLint? … Yes
✔ Would you like to use Tailwind CSS? … Yes
✔ Would you like to use `src/` directory? … Yes
✔ Would you like to use App Router? (recommended) … Yes
✔ Would you like to customize the default import alias (@/*)? … Yes
✔ What import alias would you like configured? … @/*
$ npm i && npm run dev

必要なライブラリのインストール
$ npm i microsoft-cognitiveservices-speech-sdk
環境変数の設定
$ vim .env.local
ここで先ほど取得した API キーを入力します。
NEXT_PUBLIC_AZURE_SPEECH_KEY="api key"
NEXT_PUBLIC_AZURE_SPEECH_REGION="region"
これで準備完了です。 では実際に作っていきましょう。
まず不要なものを削除していきます。
import { Inter } from "next/font/google";
const inter = Inter({ subsets: ["latin"] });
export default function RootLayout({
children,
}: Readonly<{
children: React.ReactNode;
}>) {
return (
<html lang="en">
<body className={inter.className}>{children}</body>
</html>
);
}
export default function Page() {
return <div>page</div>;
}
以下のようになれば OK

文字起こしコンポーネントの作成
新たに AzureSpeech コンポーネントを作成します。
"use client";
import React, { useState, useEffect, useRef } from "react";
import * as sdk from "microsoft-cognitiveservices-speech-sdk";
const SPEECH_KEY = process.env.NEXT_PUBLIC_AZURE_SPEECH_KEY ?? "";
const SPEECH_REGION = process.env.NEXT_PUBLIC_AZURE_SPEECH_REGION ?? "";
export const AzureSpeech = () => {
const speechConfig = useRef<sdk.SpeechConfig | null>(null);
const audioConfig = useRef<sdk.AudioConfig | null>(null);
const recognizer = useRef<sdk.SpeechRecognizer | null>(null);
const [myTranscript, setMyTranscript] = useState("");
const [recognizingTranscript, setRecTranscript] = useState("");
useEffect(() => {
if (!SPEECH_KEY || !SPEECH_REGION) {
console.error("Speech key and region must be provided.");
return;
}
speechConfig.current = sdk.SpeechConfig.fromSubscription(
SPEECH_KEY,
SPEECH_REGION
);
speechConfig.current.speechRecognitionLanguage = "ja-JP";
audioConfig.current = sdk.AudioConfig.fromDefaultMicrophoneInput();
recognizer.current = new sdk.SpeechRecognizer(
speechConfig.current,
audioConfig.current
);
const processRecognizedTranscript = (
event: sdk.SpeechRecognitionEventArgs
) => {
const result = event.result;
if (result.reason === sdk.ResultReason.RecognizedSpeech) {
const transcript = result.text;
setMyTranscript(transcript);
}
};
const processRecognizingTranscript = (
event: sdk.SpeechRecognitionEventArgs
) => {
const result = event.result;
if (result.reason === sdk.ResultReason.RecognizingSpeech) {
const transcript = result.text;
setRecTranscript(transcript);
}
};
if (recognizer.current) {
recognizer.current.recognized = (
s: sdk.Recognizer,
e: sdk.SpeechRecognitionEventArgs
) => processRecognizedTranscript(e);
recognizer.current.recognizing = (
s: sdk.Recognizer,
e: sdk.SpeechRecognitionEventArgs
) => processRecognizingTranscript(e);
}
}, []);
return (
<div className="mt-8">
<div>
<div>Recognizing Transcript: {recognizingTranscript}</div>
<div>Recognized Transcript: {myTranscript}</div>
</div>
</div>
);
};
page.tsx に AzureSpeech コンポーネントをインポートして表示します。
src/app/page.tsx
import { AzureSpeech } from "./components/AzureSpeech";
export default function Page() {
return (
<div>
<AzureSpeech />
</div>
);
}
これで完成!
ブラウザの設定からマイクとスピーカーを許可すると文字起こしが開始されます。

Recognizing Transcript は文字起こし中の文字列が出力され、Recognized Transcript は文字起こしの内容が一区切りされたところで文を整形して出力してくれます。
というこ�とで Azure Speech を用いた Nextjs での文字起こしの実装でした。
おまけ
冒頭で Azure Speech を選んだ理由として話者認識ができるという点を挙げました。
しかし公式ドキュメントをよく読んでみるとこんな記載が...

話者認識は申請をしないとできないみたいです。
というわけでワクワクドキドキで申請をしたのですが、見事に却下されました()
結局話者認識は出来ずじまいでした。
公式ドキュメントはちゃんと読みましょうね😢
おしまい。