森田です。
普段は何かしらの機能の実装の話をしてますが、今回は毛色の異なるお話をしようかと思います。
では早速こちらのコードをご覧ください。
import { useEffect, useState } from "react";
type Address = {
address1: string;
address2: string;
address3: string;
kana1: string;
kana2: string;
kana3: string;
prefcode: string;
zipcode: string;
};
export const App = () => {
const [address, setAddress] = useState<Address>();
const [loading, setLoading] = useState(true);
useEffect(() => {
const fetchData = async () => {
const response = await fetch("https://zipcloud.ibsnet.co.jp/api/search?zipcode=7830060"); //fetchでデータを取得
const data = await response.json();
setAddress(data.results[0]); //data.results[0]をaddressにセット
setLoading(false); //fetchが終わったらloadingをfalseにする
};
fetchData();
}, []);
if (loading) {
return <div>loading...</div>;
} else {
return <div></div>;
}
};
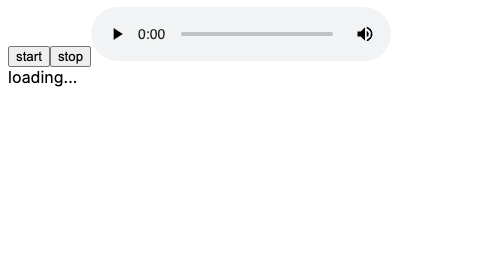
やっていることとしてページをロードした際に指定した郵便番号からどこの住所のものなのかを取得しているだけです。
fetch中はloading...と表示し、終わったら取得した内容を表示するといったページです。
では問題です。addressの型は何でしょうか。
〜シンキングタイム〜
正解は...
Address | undefinedです!正解できましたかね?
そうなんです、useStateで初期値を設定していないのでundefinedがくっついてしまうんです。
なのでaddressの値を表示させようとする��と{address?.address1}とオプショナルプロパティをつけて書かないといけなくなってしまうのです。これはよろしくないですね。
これをtypescriptの良さを活かして解決してみましょう!
解決方法としてはaddressを定義する際にその型を(Address & { loading: false }) | { loading: true }とし、その初期値を{ loading: true }とするというものです。
つまり
const [address, setAddress] = useState<(Address & { loading: false }) | { loading: true }>({ loading: true });
とするということです。
で、fetchしたデータをaddressに代入する際にloadingの値をfalseにします。
こうすることによってaddress値はundefinedにならなくなり、さらに別でloadingの値を設定する必要がなくなるのです。
文面だけだと何言ってるか少しよくわからないですね。
最初のコードを実際に編集してみましょう。
import { useEffect, useState } from "react";
type Address = {
address1: string;
address2: string;
address3: string;
kana1: string;
kana2: string;
kana3: string;
prefcode: string;
zipcode: string;
};
export const App = () => {
const [address, setAddress] = useState<(Address & { loading: false }) | { loading: true }>({ loading: true });
useEffect(() => {
const fetchData = async () => {
const response = await fetch("https://zipcloud.ibsnet.co.jp/api/search?zipcode=7830060"); //fetchでデータを取得
const data = await response.json();
setAddress({ ...data.results[0], loading: false }); //data.results[0]とloading:falseをセット
};
fetchData();
}, []);
if (address.loading) {
return <div>loading...</div>;
} else {
return <div>{address.address1}</div>;
}
};
このようにaddress.loading === falseになっている時だけaddressの値を表示するようにすると通常通り{address.address1}と表示できるようになるというわけです!
めちゃめちゃtypescriptの良さを活かしたtypescriptだからこそできる手法ではないでしょうか。
ちなみにこちらはチームのメンバーさんが見つけてくださったうひょさんの記事を参考にしています。 https://qiita.com/uhyo/items/d74af1d8c109af43849e
実際に社内のプロダクトでもこの手法を取り入れて開発をしています。
もしよかったら参考にしてみてください!
では。