森田です。
先日OpenAIのWhisperを用いた文字起こしの実装を紹介しました。ですがこの文字起こしはブラウザ上で音声を録音し、それをapiに投げて文字起こししてもらうという実装でした。
しかしこれには2つの欠点があります。まず全て録音が終了するまでちゃんと文字起こしされるかわからないという点です。もう一つは録音ファイルの容量が大きくなると文字起こしに時間がかかるという点です。
今回はこの2点を解決する方法を試験的に実装できたので、そちらを紹介したいと思います。
やったこと
今回試したのは録音を特定の秒数で区切り、その都度文字起こしをかけるという方法です。 とりあえず実装してみましょう。
実装
前回の記事で作成したwhisperHook.tsをそのまま使用します。
特定の秒数で区切るだけなので、whisperHook.tsにその処理を追加します。
import { useEffect, useRef, useState } from "react";
type Hooks = {
startRecording: () => void;
stopRecording: () => void;
isAudio: boolean;
recording: boolean;
audioFile: File | null;
isLoading: boolean;
transcript: string;
};
export const useWhisperHook = (): Hooks => {
const mediaRecorder = useRef<MediaRecorder | null>(null);
const [audioFile, setAudioFile] = useState<File | null>(null);
const [isAudio, setIsAudio] = useState<boolean>(false);
const [recording, setRecording] = useState(false);
const [isLoading, setIsLoading] = useState(false);
const [transcript, setTranscript] = useState("")
const intervalRef = useRef<number | null>(null);
const handleDataAvailable = (event: BlobEvent) => {
// 音声ファイル生成
const file = new File([event.data], "audio.mp3", {
type: event.data.type,
lastModified: Date.now(),
});
setAudioFile(file);
};
const startRecording = async () => {
setAudioFile(null)
setRecording(true);
// 録音開始
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
mediaRecorder.current = new MediaRecorder(stream);
mediaRecorder.current.start();
mediaRecorder.current.addEventListener("dataavailable", handleDataAvailable);
setIsAudio(true);
intervalRef.current = window.setInterval(() => {
mediaRecorder.current?.stop();
mediaRecorder.current?.start();
}, 5000); // 5秒ごとに録音を停止して新しい録音を開始
};
const stopRecording = () => {
setRecording(false);
// 録音停止
mediaRecorder.current?.stop();
setIsAudio(false);
};
useEffect(() => {
const uploadAudio = async () => {
if (!audioFile) return;
const endPoint = "https://api.openai.com/v1/audio/transcriptions";
const formData = new FormData();
// fileを指定
formData.append("file", audioFile, "audio.mp3");
// modelを指定
formData.append("model", "whisper-1");
// languageを指定
formData.append("language", "ja");
setIsLoading(true);
const response = await fetch(endPoint, {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.NEXT_PUBLIC_OPENAI_API_KEY}`,
},
body: formData,
});
const responseData = await response.json();
if (responseData.text) {
// 文字起こしされたテキスト
setTranscript(prev => prev + "\n" + responseData.text);
}
setIsLoading(false);
};
uploadAudio();
}, [audioFile]);
return {
startRecording,
stopRecording,
isAudio,
recording,
audioFile,
isLoading,
transcript
};
};
42〜45行目の部分で指定した秒数で録音を止めて開始するという処理を挟んでいます。今回は5秒で区切るようにしています。
intervalRef.current = window.setInterval(() => {
mediaRecorder.current?.stop();
mediaRecorder.current?.start();
}, 5000);
これで録音を開始してみましょう。すると...

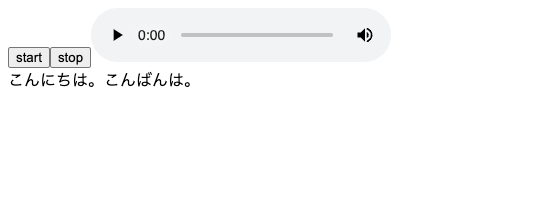
定期的に区切られてリアルタイムっぽく文字起こしされてる!🎉🎉🎉
ちなみにこちらはSREチームリーダーの山田哲さんとの今日の夜ご飯何食べようねという会話を文字起こししました。
というわけで実装できました。
欠点
前回の記事でも述べたとおり、文字起こし可能な音声が録音されていない場合に変な文字列が返ってくるという不具合がかなり影響しまして、区切るタイミングを細かくするほど顕著に現れてしまいます。 また、話の途中で区切られるとうまく文章がつながらないということもあるので、精度的にも少し懸念があります。
終わり
というわけでWhisperの文字起こしをリアルタイムっぽく実装してみました。 改善の余地はたくさんありますが、ひとまず形になったので個人的には満足しています。 whisperのsdkとか出ないかなぁ。
ではまた。