
こんにちは。リーディングマークのミキワメ適性検査開発チーム、エンジニアリングマネージャーの梶原です。
本稿では、2023年末から2024年初頭にかけて実施した「受検者データ分離プロジェクト」について解説します。このプロジェクトは、リーディングマークが提供しているミキワメ適性検査とミキワメウェルビーイングサーベイ(以下、「適性検査」「サーベイ」)のデータ構造を改善し、開発スピードの向上とシステムのスケーラビリティを実現することを目的としていました。
「受検者データ分離プロジェクト」は、2023年末に起案され、2024年1月から3月の約3ヶ月かけて開発が行われました。このプロジェクトの背景には、ミキワメ適性検査における課題がありました。従来、新卒・中途・社員の受検データを単一のテーブルで管理していましたが、事業拡大と新サービスの追加に伴い、このデータ構造が開発スピードの制約要因となっていました。
そこで、80万件を超えるデータを分割し、よりスケーラブルなシステムを構築することを目指しました。具体的には、単一のテーブルで管理していた新卒・中途・社員の3区分のデータを、3つの独立したテーブルに分割することが主な目的でした。
開発チームは、テックリード1名、適性検査開発チームから1名、サーベイ開発チームから1名の計3名で構成されました。私は主に適性検査の範囲を担当しました。
プロジェクト実施時点で、バックエンドにはRuby on Rails(バージ�ョン6.1)を使用していました。
この記事では、このプロジェクトの設計方針、技術選定、移行プロセス、直面した課題とその解決策について詳しく解説していきます。
プロダクトの課題とプロジェクト背景
前提として、弊社プロダクトのうち、適性検査・サーベイは同一のデータベースを参照しています。
ミキワメ適性検査の受検者データは、単一の examinees テーブルで管理され、新卒・中途・社員の3種類のユーザーを区別するために examinee_type カラムを使用していました。
このデータ設計では、企業に属する社員の情報を取得する際に、適性検査の受検データを経由する必要がありました。(図1)
[図1]
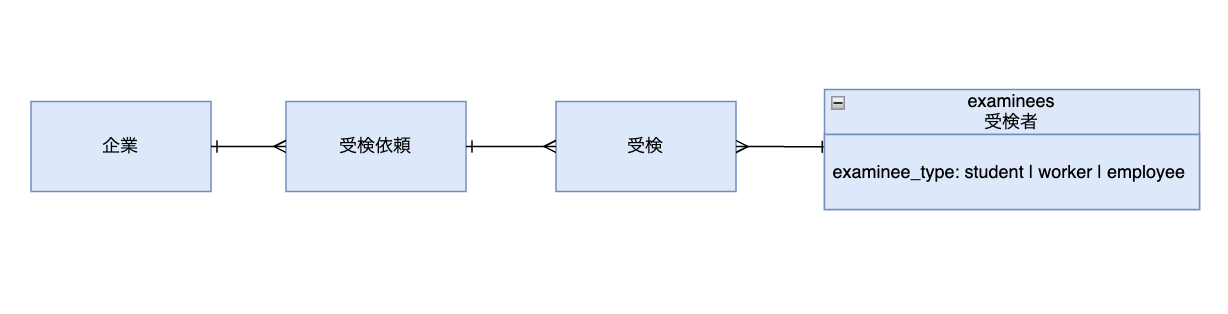
この構造では、サーベイ機能を独立させる際に不要な依存関係が生じるため、受検者のテーブルをstudents、workers、employees に分離することで直接企業と紐付けられるようにしました。受検者と紐づいている受検データにはリレーションを張っていたのですが、ポリモーフィック関連を用いて擬似的にリレーションを張ることにより、データの相関を実現する形となっています。(図2)
[図2]
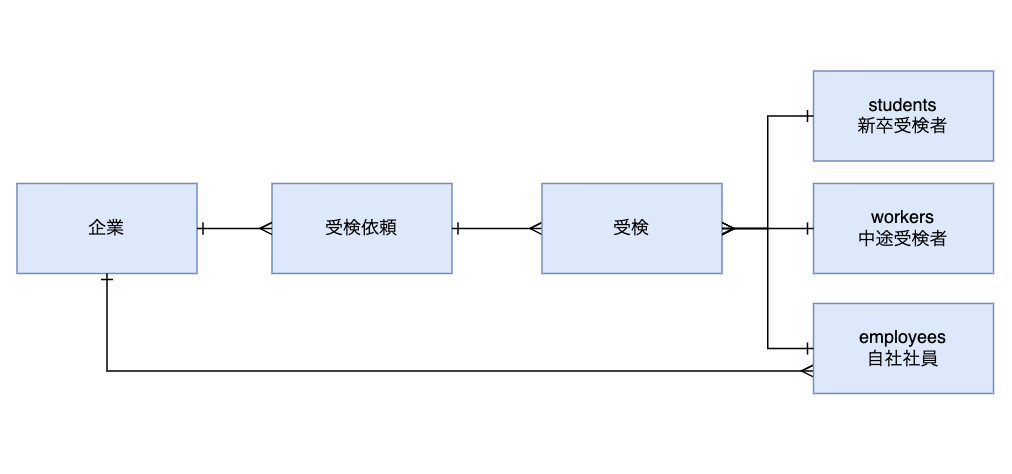
先の図1で示したプロジェクト開始前のデータ構造では、ユーザーは適性検査の受検を通じて初めて企業に属することがわかるかと思います。
この構造の問題点は、社員がサーベイに回答するには、事前に適性検査を受検して企業に属している必要があったことです。当初は運用上大きな問題にはなりませんでしたが、企業が社員に適性検査とサーベイを同時に依頼する機能を実装する際、データ上企業に属していない社員へのサーベイ発行が課題となりました。
一時的な対応も可能でしたが、将来的に社員向けサービスを展開する上で、この問題が繰り返し障害になることが予想されました。結果として、このデータ構造がプロダクト全体の拡張性を制限し、開発の難易度を高めていました。
既存の構造では、企業に属する社員の情報を取得するために、適性検査の受検依頼を介する必要があり、これは無駄に複雑な構造でした。
プロジェクトを進行するにあたっての課題
プロダクトの課題を改善できる理想状態を定義できたものの、プロジェクト進行上の課題も多く存在しました。
プロジェクトの主な課題:
- データ構造の大規模変更
受検データはプロダクトのコアであり、影響範囲が広い - ビッグバンリリースの回避
他プロジェクトと並行して進めるため、段階的な移行が必要 - データ同期の複雑性
旧テーブルと新テーブルの間で一貫性を保つ必要がある - トランザクション管理
エラー時のロールバックや同期処理の信頼性が求められる(図3)
[図3]
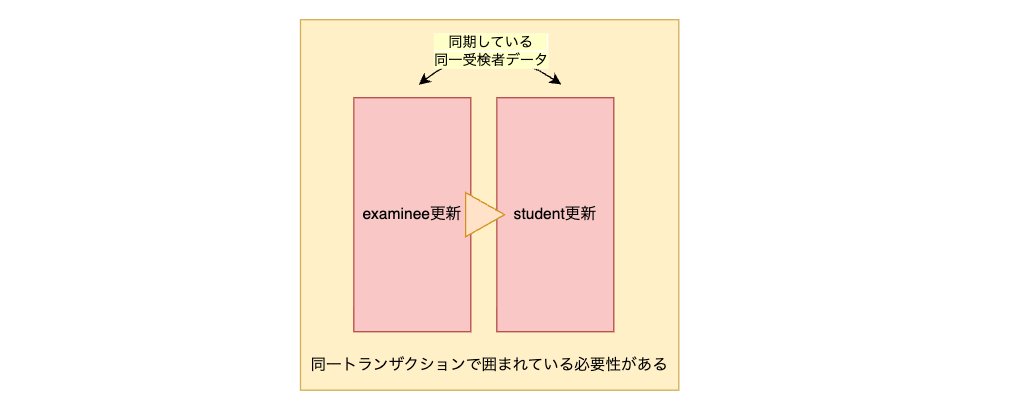
これらの複雑かつ大規模な課題に対して、システムの安定性を維持しながら��慎重に対応することが求められました。
それを考慮した上でどのような戦略を立て、どのような手順を踏んでプロジェクトを進めていったのかを説明していきます。
プロジェクト進行の戦略と手順
図4の手順に従ってプロジェクトを進行しました。
[図4]

これら手順を具体的に解説していきます。
前準備
- 受検者区分ごとに必要なカラムの精査
- 受検者情報を置き換える必要があるアプリケーションのリソースの洗い出し
- 新受検者テーブル、およびそれらの関連テーブル(サインイン情報を持つテーブルなど)の作成
新テーブル作成と既存周辺テーブルの関連付け
- 各区分の受検者テーブルへ旧受検者テーブルの情報を関連付けするためのカラム設定
- 旧受検者テーブルに対する外部キーを保持しているテーブル(受検データなど)へ、新受検者テーブルの情報をポリモーフィックで保持するためのカラムの追加、または社員のみのリレーションで十分なテーブルも存在していたため、その�場合は社員テーブルに対する外部キーのカラム追加
旧受検者データを新受検者データへ複製
約80万人(2024年1月1日時点)存在していた受検者のデータをstudents, workers, employeesそれぞれのテーブルへ移管する必要がありました。
問題点として、プロダクトリリース当初のバリデーションが十分に記述されていなかった時代に保存された受検者のデータが存在しており、それらを検知するためにいつ終わるかわからない分量のデータを移行するバッチを走らせて確認していました。
具体的には以下のような不整合のパターンが存在しました。
employeesテーブルでは現在、セイメイ(仮名姓名)の保存が必須だが、過去にはブランクが許容されていた- 新しい受検者のテーブルには、メールアドレスのフォーマットに制約があるが、以前のデータには全角英数が許容されていたりと、制約が不十分であった
このような過去データを新しい制約のあるテーブルへ複製する際、バッチ処理を実行して初めて問題に気付き、その対応に苦労しました。
最終的には、目的が「複製すること」だったので、セイメイ(姓名)のnot NULL制約などDBレベルで制約がかかっているものに関しては仮の値を、メールアドレスのフォーマットなどアプリケーションレベルで制約がかかっているものに関��しては一時的にアプリケーションの制約を外して対応することになりました。
新旧テーブル間データ同期の設定
- 旧受検者テーブルのデータに変更が加わった時に、新受検者テーブルの対応するデータも変更するための処理
- またその逆の、新受検者テーブルのデータに変更が加わった時に、旧受検者テーブルの対応するデータも変更するための処理
これらは更新・作成・削除のそれぞれで行う必要があり、モデルにコールバックを記述することで対応しました。それぞれafter_update,after_create,after_destroyを用い、同期対象となるテーブルのデータを操作する形としました。
以下のコードは、ExamineeモデルとStudentモデルにおけるコールバックの処理の記述を表したものです。(Employeeモデル, Workerモデル, update, destroyに関しては省略します。)
class Examinee < ApplicationRecord
after_update :update_student
private
def update_student
self.student.update!(**{some_attributes})
end
end
class Student < ApplicationRecord
after_update :update_examinee
private
def update_examinee
self.examinee.update!(**{some_attributes})
end
end
コールバック内でデータを操作する処理の中で仮にエラーが発生した場合、トランザクションはどうなるのかという問題がありましたが、最初に操作を受けたテーブルのデータの処理からコールバック内で発火したデータ操作の処理は、同一トランザクションで囲まれる形となっているため、特段気にすることなくコールバックの記述をすることができました。
しかしながらここには一点問題があり、例えばExamineeの更新がコールバックでStudentの更新を呼んだ時、Studentの更新もコールバックでExamineeの更新を呼んで��、さらにまた、、、という無限ループが発生してしまいます。
この無限ループ問題に対して、他社事例も参考にしながらの対処を行いました。
まず、両方のモデルでattr_accessorを使用して、一時的なインスタンス変数skip_double_writeを定義します。このようにすることで、インスタンスのライフサイクルの中でしか存在しないskip_double_write がそれぞれのActiveRecordインスタンスのカラムのように振る舞います。
このキーを、Examineeクラスのコールバックで呼ばれるプライベートメソッド内でtrueとしてStudentインスタンスに受け渡し、Studentクラスのコールバックの発火条件として利用することで、「ExamineeクラスのコールバックでStudentインスタンスが更新された場合、StudentクラスでExamineeインスタンスの更新を行うコールバックを発火しない」という、更新が再帰的に発生しないような挙動の実現が可能となります。
一部簡略化していますが、具体的なコードとしては以下です。
class Examinee < ApplicationRecord
attr_accessor :skip_double_write
after_update :update_student, unless: :skip_double_write
private
def update_student
self.student.update!(**{some_attributes}, skip_double_write: true)
end
end
class Student < ApplicationRecord
attr_accessor :skip_double_write
after_update :update_examinee, unless: :skip_double_write
private
def update_examinee
self.examinee.update!(**{some_attributes}, skip_double_write: true)
end
end
これらの設定を行うことにより、無事同期的にデータの整合性を保つ仕組みを整えることができました。もちろんここにはパフォーマンス観点で問題がありましたが、ここに関しては一定許容していただきつつ運用することとなりました。
アプリケーションが参照しているテーブルを旧テーブルから新テーブルへ全て移行
ここでは前述したように、段階的に既存処理の移行を図りました。
当時、30以上の機能が旧受検者を参照している形であったため、その全てを新受検者のテーブルへ移管する必要がありました。
ここに関しては特に何かを工夫したわけではありませんでしたが、一つ一つドメインを把握している必要があり、入社2年弱であった私もキャッチアップから入る箇所もあったため、正直一番大変な作業でした。
ただ移行作業をするだけでなく、一部大きく処理を変えなければならない箇所も出てきました。
例えば受検データの検索においては、受検者のメールアドレスなどで検索することができるUIが存在していて、その場合関連テーブルとしてexaminees単体の検索で良かったものが、students, workers, employeesそれぞれを跨いだ検索ができるような機能に修正する必要がありました。
そのほかにも煩雑なコードやロジックが残されている箇所に関しては、そのまま移行するのではなく、全体的なリファクタリングを行った上で移行作業をしていったり、そもそも機能をほぼ作り直したような箇所もあったため、思ったようにタスクが消化できない時もありましたが、最終的には無事に移行作業を完了することができました。
対応漏れログの抽出用の設定
移行作業は完了したものの、間髪入れずにexamineeクラスを削除するのはリスクが高かったため、実際にexamineeが呼ばれている箇所がないかをログとして抽出できるように、examineeクラスに以下のような記述をしました。
after_initialize do |_examinee|
backtrace = caller.grep(/#{Regexp.escape(Rails.root.to_s)}/)
Rails.logger.info "Examinee initialize. #{backtrace}"
end
after_find do |_examinee|
backtrace = caller.grep(/#{Regexp.escape(Rails.root.to_s)}/)
Rails.logger.info "Examinee find. #{backtrace}"
end
after_initializeでexamineeインスタンスが初期化された後、また、after_find でexamineeモデルを介してデータベースに検索をかけにいった際に、ログを残すような仕組みを残しました。
こうすることで、一定期間ユーザーがサービスを実際に利用する中で本当にexamineesテーブルに対する取得や操作は行われていないのかを確認することができます。
このおかげで、レガシーとなったexamineeモデルを安心して削除できるような状態を実現できています。
旧受検者モデルの削除
対応漏れの確認と検証を十分に行った上で、アプリケーションから旧受検者であるexamineeの概念を取り除きます。
アクセスがされないモデルが残ってしまうため、モデルとそれらに関連するファイルを削除しました。
移行先の新テーブルにデータは残っていますが、念の為旧テーブルのデータ自体の削除は一定期間行わない方針です。
プロジェクトを振り返って
このプロジェクトを通じて、データ構造のシンプル化と、プロダクトの拡張性向上を実現しました。
特に、段階的な移行戦略やデータ同期の仕組み、トランザクション管理の工夫は、同様の課題を抱えるエンジニアにとって参考になるポイントかと思います。
今後も、システムの進化に合わせて最適なデータ設計を模索しながら、継続的に改善を進めていきます。