はじめに
初めまして、株式会社リーディングマークで1on1のプロダクト開発を担当しているエンジニアの藤崎です。
今夏、新しいプロダクトの開発に携わりました。
そのプロダクトでは、長い文章を入力するフォームがあります。
その課題として、長時間のフォーム入力中にデータが消失するリスクが懸念されていたので、自動保存機能をつけるという要件が上がってきました。 Webアプリケーションでフォーム入力中にデータが消えてしまう体験は、ユーザーにとって大きなストレスです。
本記事では、自動保存機能を実装するためのアプローチや工夫した点について解説してみました!
環境情報
- Ruby 3.3.5
- Rails 7.0.8.6
- Node.js 20
- React 18.2.0
- TypeScript 5.0.4
課題:自動保存とバリデーションの両立のジレンマ
自動保存機能を実装するにあたって、「保存」と「バリデーション」のジレンマが存在します。
例えば、googleフォームのようなアンケート回答システムを考えてみましょう。
回答テーブルに対して、自動保存機能をつけたいです。
求められるバリデーションとしては、必須回答(空文字を許容しない)、文字数制限10000文字などが想定できます。
この時、自動保存機能を実装するには、以下の2つが両立する必要があります。
- 自動で保存が実行されること ― ユーザーの操作なしに、バックグラウンドで保存が走る
- データが正しく保存されること ― 不正なデータがDBに入り込まない
一見当たり前に思えるこの2つですが、実際には両立が困難です。
なぜ難しいのか
バリデーションを設定した場合、入力途中のデータは未入力などにより、バリデーションエラーとなる可能性があります。そうなると、自動保存の最大の恩恵である「勝手に自動で保存してくれる」という体験が損なわれてしまいます。
かといって、バリデーションを外してしまうと、無制限の文字数や不正なデータがそのまま保存され、DBを破壊するリスクを抱えることになります。
結論、解決策は以下の通りです。
-
テーブル分割
自動保存用の下書きテーブルと、確定保存用の清書テーブルの2つのテーブルを用意する。
-
下書きテーブルへの自動保存
バリデーションをなるべく最低限にする。今回の例で言うと、入力必須にはしないが、DB破壊リスクを防ぐための文字数制限��だけ設定する。
また、文字数制限超過のバリデーションエラーの場合、フロントでエラーを表示させ、保存できる入力箇所だけを保存する
-
清書テーブルへの保存
入力完了後、保存ボタンからユーザに手動保存してもらう。ここではバリデーションを完全なものにする。バリデーションエラーが発生した場合は、ページ上にエラーを表示する
このあと詳細を記載します。
解決策:下書きテーブルの分離
下書き用のテーブルと清書用のテーブルを分離します。
| 下書きテーブル | 清書テーブル | |
|---|---|---|
| 保存タイミング | 入力変更後 1秒 debounce で自動保存 | 送信ボタン押下時 |
| バリデーション | 文字数上限のみ(10,000文字) contentは NULL許容 | 文字数上限(10,000文字) contentは NOT NULL |
| 目的 | データ損失防止 途中離脱しても安心 ブラウザクラッシュ対策 | 正式データとして確定 |
CREATE TABLE answers (
id BIGSERIAL PRIMARY KEY,
question_id BIGINT NOT NULL REFERENCES questions(id),
user_id BIGINT NOT NULL,
content TEXT NOT NULL CHECK (char_length(content) >= 10), -- 必須 & 最低10文字
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(question_id, user_id)
);
ER図
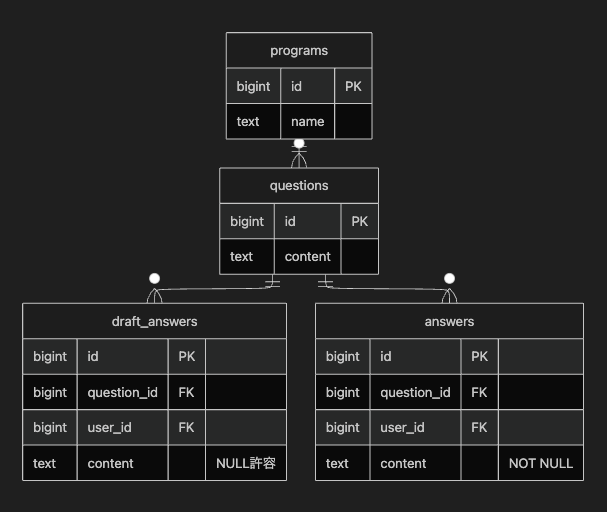
下書きデータのcontentにはバリデーションを設定していませんが、 清書データのcontentにはバリデーションを設定しています。 これによって、入力中はユーザーの入力を寛容に受け入れることができます。
ただ、テーブルが分かれることによって、様々なことに考慮しなければなりませんでした。
フロントエンド工夫点1:Debounce処理による自動保存
const triggerAutoUpdate = useCallback(
(onboarding: Onboarding) => {
if (autoSaveTimeoutRef.current) {
clearTimeout(autoSaveTimeoutRef.current);
}
autoSaveTimeoutRef.current = setTimeout(async () => {
await saveOnboarding(onboarding);
}, debounceMs);
},
[saveOnboarding, debounceMs]
);
ユーザーが入力操作を行いフォームの中身が変化するたび、 triggerAutoUpdate が呼ばれるので、連続入力中の過度なAPIリクエストを防止するようにしました。
- 既存のタイマーがあればクリアし、新しいタイマーをセット
- 最後の入力から debounceMs(1000ms)経過後にAPIリクエストを送信
フロントエンド工夫点2:入力変更時のハンドラ
const handleBasicInfoResponseChange = useCallback(
(key: keyof NewBasicInfoResponse, value: string) => {
// ...バリデーションエラーのクリア...
setBasicInfoResponse((prev) => {
const updated = { ...prev, [key]: value };
triggerAutoUpdate(buildOnboardingData({ basicInfoResponse: updated }));
return updated;
});
},
[triggerAutoUpdate, buildOnboardingData, validationErrorsState.basicInfoErrors]
);
状態更新と同時に triggerAutoUpdate を呼び出し、全ての入力項目をまとめて buildOnboardingData でオブジェクト化
これによって、setState のコールバック内で updated を作成し、その場でAPIに渡すので、100%最新の値が送信されることが保証されます。
フロントエンド工夫点3:送信前の強制保存
const forceSave = useCallback(
async (onboarding: Onboarding) => {
if (autoSaveTimeoutRef.current) {
clearTimeout(autoSaveTimeoutRef.current);
autoSaveTimeoutRef.current = null;
}
await saveOnboarding(onboarding);
},
[saveOnboarding]
);
入力して、すぐに清書ボタンがクリックされてしまうと、入力中のものは更新インターバルが1秒あるので、その間に入力された値が反映されずに、清書されてしまうことがあります。
これを懸念して、フォーム送信時に forceSave を使用しました。
バックエンド工夫点1:清書保存のためのサービスクラス
DraftOnboardingFinalizer
def finalize
result = Onboarding::DraftOnboardingFinalizer.new(employee: current_user, program: program).call
...
end
class Onboarding::DraftOnboardingFinalizer
Result = Data.define(:success?, :errors)
def initialize(employee:, program:)
@program = program
@employee = employee
@errors = []
end
def call
check_validations_for_draft_answers
if errors.empty?
finalize_onboarding
Result.new(success?: true, errors: {})
else
formatted_errors = format_errors
Result.new(success?: false, errors: formatted_errors)
end
end
def check_validations_for_draft_answers
return if draft_answers_response.valid?
draft_answers.errors.each do |error|
errors << {
type: :draft_answers,
field: error.attribute.to_s,
message: error.full_message
}
end
end
...
end
保存処理はサービスクラスに切り分けています。
draftデータが存在しているか、清書可能なデータ状態か、部分的に保存が成功したのかどうかなど、構造体resultとして情報を返しています。
バックエンド工夫点2:アクセス制御
def answer_finalized?(employee_id)
# 清書レコードが存在しているか
end
def onboarding_auto_saved?(employee_id)
# draftレコードが存在しているか
end
また、自動保存の状態は3パターンに分かれていて、それらによる画面アクセス制御も行いました。パターンは以下のように分かれます。
- パターン1:自動保存が一度もされていないパターン
- パターン2:自動保存が少なくとも1度はされているが、清書が未完了のパターン
- パターン3:自動保存が少なくとも1度以上されていて、清書が完了しているパターン
自動保存を実現するためにはテーブルをわけ、それのユーザの入力状態によって、各機能のアクセス制御も分岐するという点はよく考えておく必要があるなと実感しました。
application_controller.rb
# パターン1(未回答)でアクセスできる画面
ACCESSABLE_UNSAVED_PATHS = [
'/',
].freeze
# パターン2(回答中)でアクセスできる画面
ACCESSABLE_ANSWER_IN_PROGRESS_PATHS = [
'/',
// ...
].freeze
# パターン3(回答済)でアクセスできる画面
ACCESSABLE_ANSWER_COMPLETED_PATHS = [
'/',
// ...
].freeze
良くできたこと
-
アクセス制御の保守性
設計段階では、各画面のアクセス制御を各controllerのbefore_actionで実装する予定でした。しかしその方法だと、アクセス制御のエラーハンドリングを、各controllerで処理することになるため、アクセス制御の全体像を見通すことができなくなってしまいます。
そうなると、機能の追加時などに考慮漏れなどが発生する可能性が高まったり、キャッチアップの負荷が増加したりと、保守性が悪化すると考えました。
そこで、「バックエンド工夫点2:アクセス制御」で記述したapplication_controllerに処理をまとめる方法で、解決しました。
controllerのbefore_actionで、そのcontroller特有のエラーハンドリングをすることは良いですが、機能全体に共通するような処理は、application_controllerに切り出すことが重要であることを学びました。
今後の開発でもここは留意していきたいなと考えております!
もっと良くできたこと
-
オフライン対応
現状ではオンライン前提となっているので、ネットワーク切断時にlocalStorageに一時保存しておき、オンライン復帰後に同期する仕組みがあると更に便利になるかなと思っています。
-
自動保存時の通知
自動保存が実行されたタイミングで、「保存されました」と言うような旨の通知がポップされると、ユーザー視点自動保存がされたことが認知できて、安心して入力作業を進められるようになると思います。
おわりに
本記事では、プロダクトに自動保存機能を持たせたい場合の弊社で実装した試みをまとめてみました。
今までの自分の開発経験としては、自動保存は初めてで、最初は全く実装イメージが沸いていませんでした。チーム内でどう実現するのが良いか、じっくり皆で詰めていった結果、今の自信を持てる形が実現できたと思っています。
以上になります!
今後とも、チームで協力してより良いプロダクトを作っていけたらと考えています!