こんにちは。サービス開発部/プロダクト開発部門/従業員サーベイチームのエンジニアリングマネージャー、中川優です。
弊社では、ミキワメ適性検査・ミキワメウェルビーイングサーベイ・ミキワメマネジメントなど複数のプロダクトを展開しており、これらプロダクトごとに様々なタイミングでユーザーへの通知が届きます。
2025年初頭、Slack連携機能を追加するための開発が決定し、同年春のリリースを目指して、メールに加えて複数の通知チャネルを安全かつ簡潔に扱う仕組みづくりが課題となりました。
このプロジェクトは無事に2025年春にリリースを迎え、現在では多くのお客様にSlack通知機能をご活用いただいています。 リリースから半年以上が経過した現在のタイミングで、当時の設計思想を振り返ってみたいと思います。
プレスリリース:ミキワメ適性検査、Slack連携機能をリリース
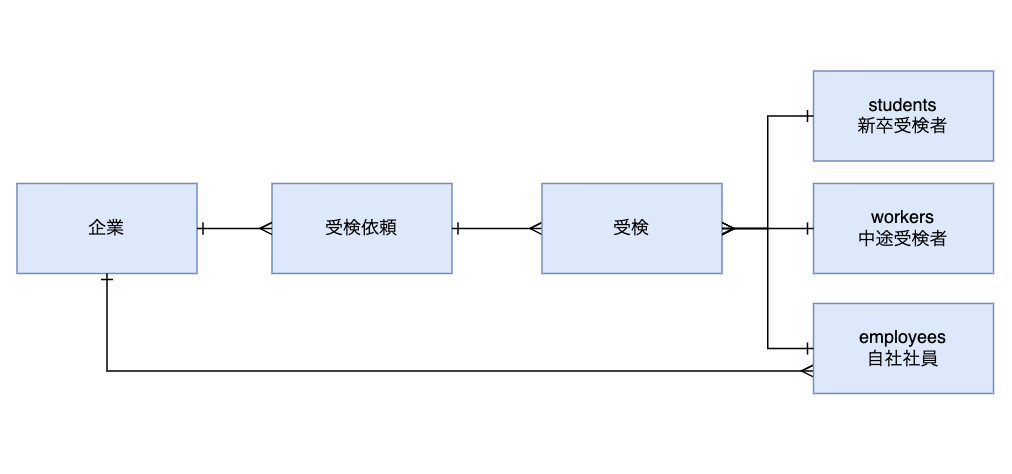
※用語メモ:
- 「受検」は適性検査の受検依頼
- 「サーベイ」はウェルビーイングサーベイにて配信されるアンケート
本記事では、複数プロダクトで統一的なメール・Slack通知を実現するために設計した通知基盤について解説します。
複数プロダクトでの通知チャネル追加の複雑さ
着手時の状況
主要プロダクトのそれぞれで、複数の通知機能が存在しています。
- 適性検査: 受検依頼、受検リマインド、受検結果完了通知、など
- サーベイ: 回答依頼、回答リマインド、集計完了通知、など
これらは全てメール通知として実装されており、各プロダクトのコードベースに散在していました。
新たな要件
Slack連携機能の追加により、以下の要件が発生しました。
- メール通知は従来通り、通知先アカウントに対して必須である
- Slack通知は、企業がSlack連携済みの場合のみに限る
設計上の課題
単純に、既存の通知実装にSlack送信の処理を追加する案も考えましたが、以下の問題が発生することを容易に想像できてしまい、正直に言うとかなり気が重かったです。
- 通知の実装箇所ごとにSlack連携有無判定チェックが重複(DRYじゃない)
- Slack API周辺のロジックが各プロダクトに散らばり、「どこで何が送られているのか」が分からなくなるカオス
- 送信順序や失敗時の処理が分散され、デバッグ時の確認箇所を増やす羽目になる
解決策:単一の呼び出し口としてのクラスを基盤とする設計
設計上の課題を解決するため、以下の通知基盤を実装しました。
- 単一の呼び出し口:呼び出し側は1つメソッドを呼ぶだけで、メール・Slack両方の通知に対応できる
- チャネルの透過性:呼び出し側はメールとSlackの技術的詳細の違いを意識する必要がない
- Slack未連携企業でも、メール通知は確実に届くことを担保する
処理フロー
通知基盤の各メソッドは、以下の流れで処理を行います:
- メール送信(必須)
- Slack連携チェック
- 送信対象のフィルタリング
- Slack通知本文のメッセージ生成
- Slack API実行用非同期Job投入
この順序により、Slack送信の成否に関わらずメール通知は確実に送信させることができます。
通知基盤の実装
※本記事のコード例は説明のため一部簡略化・抽象化しています。
コード構造
適性検査の受検依頼用のメソッドを例に説明します。
class MultiChannelNotifier
def send_examination_notification(company_id, recruitment, template, user_ids)
# 1. メー��ル送信(必須)
MailService.call(company_id:, recruitment:, template:, user_ids:)
# 2. 企業のSlack連携設定状況のチェック(オプショナル)
slack_connection = SlackConnection.find_by(company_id:)
return unless can_slack_send?(
slack_connection,
required: -> { recruitment.target_type.employee? }
)
# 3. 送信対象取得
targets = recruitment.employees.where(id: user_ids)
# 4-5. メッセージ生成 & 非同期送信
slack_bulk_send_process(slack_connection, targets) do |employee|
content = SlackMessageBuilder.call(company_id:, recruitment:, employee:)
{ user_email: employee.email, content: }
end
end
private
def can_slack_send?(slack_connection, required: nil)
slack_connection.present? && (required.nil? || required.call)
end
def slack_bulk_send_process(slack_connection, targets)
direct_messages = targets.map do |target|
message_data = yield(target)
SlackDirectMessage.new(
recipient_email: message_data[:user_email],
content: message_data[:content]
)
end
SlackBulkSendJob.perform_async(
slack_connection.id,
direct_messages.map(&:to_h)
)
end
end
条件分岐の設計
can_slack_send? メソッドがチェックする条件は下記の通り。
| 条件 | 説明 |
|---|---|
| Slack連携の有無 | Slack連携情報(その企業がSlackと連携中にのみ存在する)の存在確認 |
| 通知機能固有条件 | requiredパラメータで指定(オプショナル)。未指定の場合は考慮されない。 |
通知機能固有条件の例:
前述したコード例の recruitment.target_type.employee? の部分が固有条件に相当します。これは、適性検査の受検依頼をする対象者のアカウント種別が自社社員かどうか?を確認していることを表しています。
※ミキワメでは、自社社員の他、新卒候補者や中途候補者などのアカウント種別が存在します。
この設計により、通知機能ご��との細かい条件分岐を柔軟に実装できるようになりました。
Slack通知基盤の詳細
Slack通知は以下のレイヤー構成で実装しています(名称は簡略化しています):
MultiChannelNotifier(呼び出し口)
↓
SlackSendJob / SlackBulkSendJob(非同期処理)
↓
SlackSingleSender / SlackBulkSender(サービス層)
↓
SlackApiChat / SlackUsersApi(APIラッパー)
↓
Slack::Web::Client(slack-ruby-client gem)
「後から見たときに、どこを直せばいいか分かる構造にしたい」という思いで、責務が明確になるようレイヤーを分離しました。これにより、テストもしやすく保守性の高い設計になったと感じています。
slack-ruby-client gemの選定理由
https://github.com/slack-ruby/slack-ruby-client
- Slack API仕様に準拠したインターフェース
chat.postMessageやusers.lookupByEmailなどの要件上必要なメソッドが提供済みTooManyRequestsErrorにretry_after属性が含まれるなど、Slack特有のエラー処理が組み込まれている
- 定期的なメンテナンスが入っており、Star数も1.3k超(2025年12月時点)
- READMEが充実しておりトラブルシューティングがしやすい
slack-ruby-clientを介さず、Faradayで直接実装することも検討しましたが、エンドポイントのパス管理、パラメータの組み立て、エラーレスポンスの解釈などを全て自前で実装・保守する必要があり、保守コストが相対的に高いと判断しました。
※slack-ruby-clientは内部的にFaradayを使用しているため、HTTPクライアントとしてのFaradayの利点は享受しつつ、Slack API特有の処理を抽象化できています。
主要なクラス(名称は簡略化しています)
| クラス | 役割 |
|---|---|
SlackConnection | 企業ごとのOAuth認証情報を保持するActiveRecordモデル |
SlackDirectMessage | メッセージのValue Object(4000文字制限に対応) |
SlackApiBase | リトライ処理・レートリミット対応の基底クラス |
SlackBulkSender | users.listで全ユーザー取得後、メールでフィルタして並列送信 |
SlackSingleSender | users.lookupByEmail でユーザーを一件取得し、見つかった場合に送信 |
単発送信 vs 一括送信
Slack APIの呼び出し回数を最適化し、送信対象の人数に応じて2つの方式を使い分けています:
| 方式 | APIコール | 用途 |
|---|---|---|
| 単発送信 | users.lookupByEmail → chat.postMessage | 1人への通知 |
| 一括送信 | users.list → chat.postMessage × N | 複数人への通知 |
一括送信では、事前にusers.listで全ユーザーを取得し、メールアドレスでマッチングすることで、users.lookupByEmailの呼び出し数を削減しています。
リトライ処理とレートリミット対策
Slack APIを使用したユーザーへのメッセージ送信には、chat.postMessage というエンドポイントを使用する必要があります。
このエンドポイントのリクエスト制限に至る上限値は公開されていないため、いつ制限に至るか読むことが困難です。そのため、あらかじめレートリミット時のエラーハンドリングを適切に行う必要がありました。リトライ処理を共通化した基底クラスを用意し、ここでリトライ処理を実装しています。
対応するエラー
| エラー | 対策 |
|---|---|
| レートリミット | レスポンスに含まれるretry_afterの秒数だけ待機して再試行 |
| 予期しないタイムアウト | 指数バックオフで最大数回リトライ |
実装コード例(簡略化しています)
※実運用では、リトライ上限の設定やデッドレターキュー(DLQ)への退避など、ジョブが長時間滞留しないための仕組みも併せて検討することをおすすめします。
class SlackApiBase
def initialize(credentials:)
@credentials = credentials
end
private
attr_reader :credentials
def client
@client ||= Slack::Web::Client.new(token: credentials)
end
def with_retry(method_name:, max_retries:)
begin
yield
rescue Slack::Web::Api::Errors::TooManyRequestsError => e
# レートリミット: Slackが指定した秒数だけ待機して再試行
...
rescue Slack::Web::Api::Errors::TimeoutError => e
# タイムアウト: 指数バックオフで再試行
...
end
end
end
# chat.postMessageへのリクエストを実行する継承クラスでwith_retryを使用するようにしている
class SlackChatApi < SlackApiBase
def post_message(channel:, text:)
with_retry(method_name: 'post_message') do
client.chat_postMessage(channel:, text:)
end
end
end
設計のポイント
- レートリミット対応:Slack APIは
retry_afterヘッダーで待機時間を指定するため、それに従うことで確実にリトライできます - タイムアウト対応:一時的なネットワーク障害に対応するため、指数バックオフで再試行します
一括送信時の処理
一括送信では、レートリミットを考慮しつつ効率的に送信するため、以下の方針で実装しています:
- 一定件数ごとにバッチ処理
- 複数スレッドで並列にAPIコール
- 各APIコールは
with_retryでラップされており、エラー時は自動リトライ
この設計により、大量のユーザーへの通知でもレートリミットに引っかかることなく、送信処理を維持することができます。
メッセージ生成の設計
各プロダクトで、通知種別ごとにメッセージ本文の文字列を戻り値とするSlackMessageクラス(PORO)を配置しています。
各クラスは単一責務の原則を守り、1つの通知種別のみを担当するようにしています。
# モジュラーモノリス構成のイメージ(実際の構成とは異なります)
packs/
├── product_a/app/services/
│ ├── user/slack_message/
│ │ ├── notification_type_1.rb # ユーザー向け通知
│ │ └── ...
│ └── admin/slack_message/
│ ├── notification_type_2.rb # 管理者向け通知
│ └── ...
├── product_b/app/services/
│ ├── user/slack_message/
│ │ ├── notification_type_3.rb
│ │ └── ...
│ └── ...
└── ...
この設計で得られたメリット
1. 呼び出し側のシンプルさ
新しい通知を追加する際、MultiChannelNotifierにメソッドを1つ追加するだけで、メール・Slack両方に対応できます。
2. 技術的詳細とビジネスロジックの分離
- 通知基盤クラス:「いつ、誰に通知するか」というビジネスロジックを担当
- Slack送信サービス:「どうやってSlackに送信するか」という技術的詳細を担当
この分離により、Slack APIの仕�様変更があっても、通知基盤側の変更は不要です。
今後の課題と改善点
大規模企業での送信速度と、将来的な新チャネル追加を見据えた拡張性が主な検討ポイントです。
1. エンプラ企業向けの高速化
現在の実装では、レートリミットを考慮して並列数を抑えて送信していますが、実装時の計測時は100通弱程度から制限がかかることが多かったです。したがってエンプラ規模の企業では通知完了までにかかる時間が増大してしまう可能性が残っています。
今後の改善案として、並列処理のスレッドごとにSlack Appを割り当てるなど、インフラ側でのスケーリング前提の対応なども検討する必要があります。
2. 通知基盤クラス自体のリファクタ
現在はメールとSlackのみですが、今後Microsoft TeamsやLINE WORKSなど、他のチャネルへの対応も考えられます。
その際は、以下のような設計変更を検討する必要があると考えています。
- チャネルごとのStrategyパターンの導入
- 通知設定の柔軟な管理(企業ごとに有効なチャネルを選択可能に)
まとめ
本記事では、複数プロダクトで統一的にメール・Slack通知を実現する通知基盤について解説しました。
この設計により、以下を実現できました:
- 呼び出し側のシンプルさを保ちながら、複数チャネルへの通知を実現
- slack-ruby-clientを活用した安定的なSlack API連携
- Slack APIの技術的詳細を隠蔽し、保守性を向上
- Slack未連携企業への影響なし
正直なところ、レートリミットの挙動が読めない中での実装は特にきつさを感じました...!公式ドキュメントには上限値が書かれていないため、「100通目くらいで制限がかかるな」「並列数はどの程度なら安定するか」といった感覚を、実際に送信テストを繰り返しながら掴んでいく必要がありました。この試行錯誤の部分が、特に苦労したポイントです。
抽象化を目的としたクラスを設けたことで、各プロダクトのビジネスロジックとSlack APIの技術的詳細の直接的な依存を避けることができました。この設計判断により変更容易性が大きく向上し、リリース後も新しい通知種別の追加がスムーズに行えています。
今後も、ユーザー体験を向上させるため、通知基盤の改善を続けていきます!